در دنیای نرمافزارهای امروزی، دیگر کافی نیست که یک سرویس فقط «کار کند». کاربر انتظار دارد سرویس همیشه در دسترس باشد، سریع پاسخ دهد، در زمان اوج ترافیک از پا نیفتد، و در صورت رخ دادن خطا، سریع و قابلپیشبینی بازیابی شود. در همین نقطه است که Site Reliability Engineering یا SRE وارد میشود؛ رویکردی که گوگل آن را نه فقط یک نقش شغلی، بلکه یک job function، mindset و مجموعهای از engineering practices برای اجرای سیستمهای production قابلاعتماد توصیف میکند.
SRE در سادهترین بیان، یعنی تبدیل reliability از یک کار واکنشی و دستی، به یک discipline مهندسیشده، قابلاندازهگیری و تکرارپذیر. در توصیف رسمی Google Cloud، SRE در گوگل یعنی «تعریف مداوم اهداف قابلیت اطمینان، اندازهگیری آن اهداف، و کار کردن برای بهبود سرویسها در صورت نیاز». این یعنی SRE فقط نگهداری سیستم نیست؛ یک روش تصمیمگیری برای balancing میان رشد محصول و پایداری سیستم است.
اگر هنوز با فلسفه DevOps و نقش آن در همکاری بین توسعه و عملیات آشنا نیستید، پیشنهاد میکنیم ابتدا مقاله «DevOps چیست؟ راهنمای کامل از صفر تا حرفهای (۲۰۲۶)» را مطالعه کنید تا بهتر متوجه شوید SRE در چه نقطهای از تکامل DevOps قرار میگیرد.
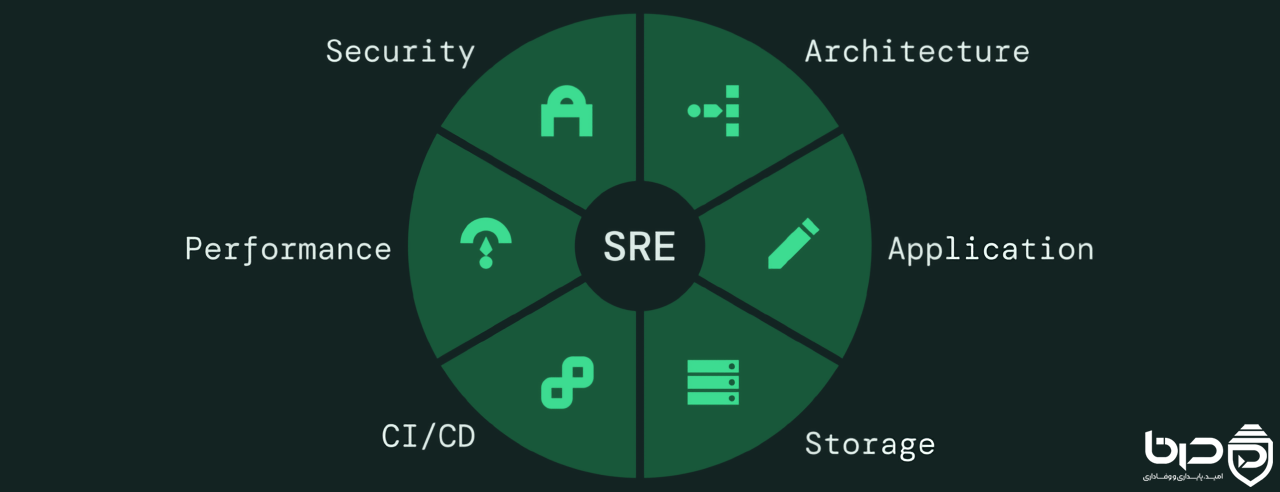
چرخه SRE شامل Security، Architecture، Application، Storage، CICD و Performance👇
۱. SRE دقیقاً چیست؟
SRE یعنی بهکارگیری اصول مهندسی نرمافزار برای حل مسائل عملیات، reliability و scalability. گوگل در صفحه رسمی SRE خود این حوزه را بهعنوان رویکردی برای running reliable production systems معرفی میکند، و در نوشتههای آموزشیاش تأکید دارد که SRE یک framework برای measurement، prioritization، information sharing و استفاده از automation است تا تیمها بتوانند بین سرعت release و رفتار پیشبینیپذیر سرویسها تعادل برقرار کنند.
مثال سادهاش این است: در مدل سنتی، وقتی یک سرویس down میشود، تیم عملیات وارد عمل میشود، دستی بررسی میکند، مشکل را پیدا میکند و بعد از بحران، شاید automation اضافه شود. در SRE، از ابتدا طراحی سیستم باید بهگونهای باشد که metrics، alerting، on-call، incident response، postmortem و automation از دل معماری بیرون بیایند، نه اینکه بعداً به سیستم چسبانده شوند. همین نگاه باعث میشود SRE یک discipline پیشگیرانه باشد، نه صرفاً یک تیم fire-fighting.
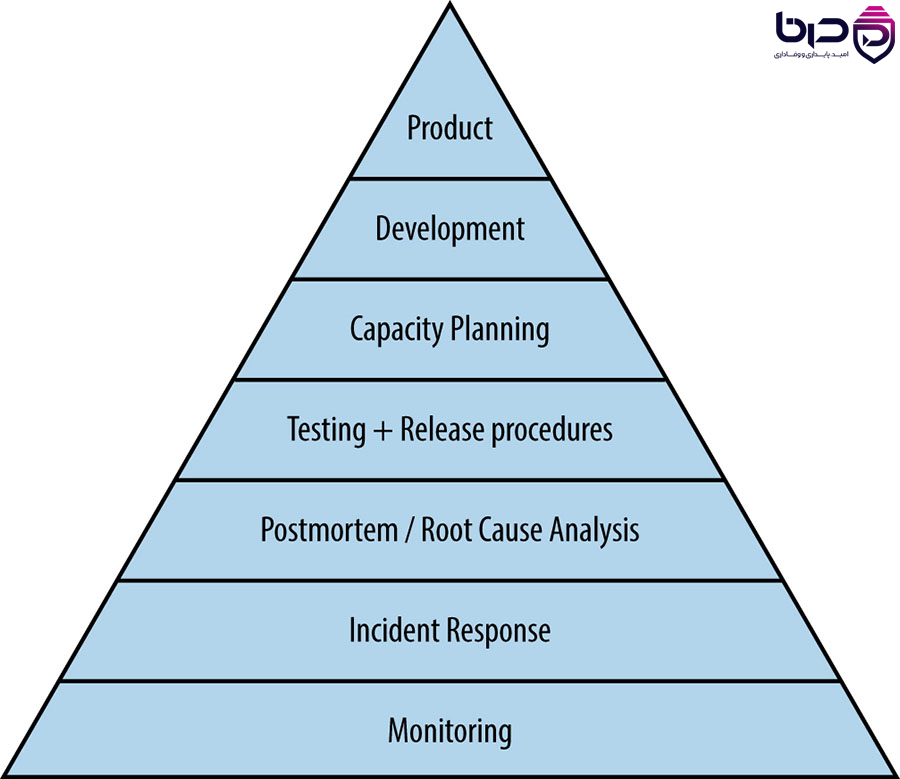
هرم SRE - Monitoring، Incident Response، Postmortem، Testing، Capacity Planning، Development و Product👇
۲. SRE چرا بهوجود آمد؟
گوگل توضیح میدهد که در روزهای ابتدایی رشد محصولاتش، عملیات فنی بیشتر بهصورت manual و واکنشی انجام میشد؛ اما با افزایش سریع کاربران و پیچیدگی سیستمها، این مدل دیگر scalable نبود. Google Cloud صریح میگوید که این رویکرد سنتی نمیتوانست همپای رشد سیستمها حرکت کند و نیاز به سرمایهگذاری غیرقابلتحمل در نیروی عملیات ایجاد میکرد. همین تجربه، گوگل را به سمت SRE برد.
این یعنی SRE از دل یک نیاز واقعی بیرون آمد: سیستمهای بزرگ، توزیعشده و همیشهروشن را نمیشود با روشهای دستی و ad hoc مدیریت کرد. در چنین محیطی، هرچه serviceها بیشتر، deploymentها سریعتر و dependencyها پیچیدهتر شوند، احتمال failure هم بیشتر میشود. SRE پاسخ به همین واقعیت است: اگر failure بخشی از زندگی سیستم است، باید مکانیزمی مهندسیشده برای پذیرش، اندازهگیری، محدودسازی و یادگیری از آن داشته باشیم.
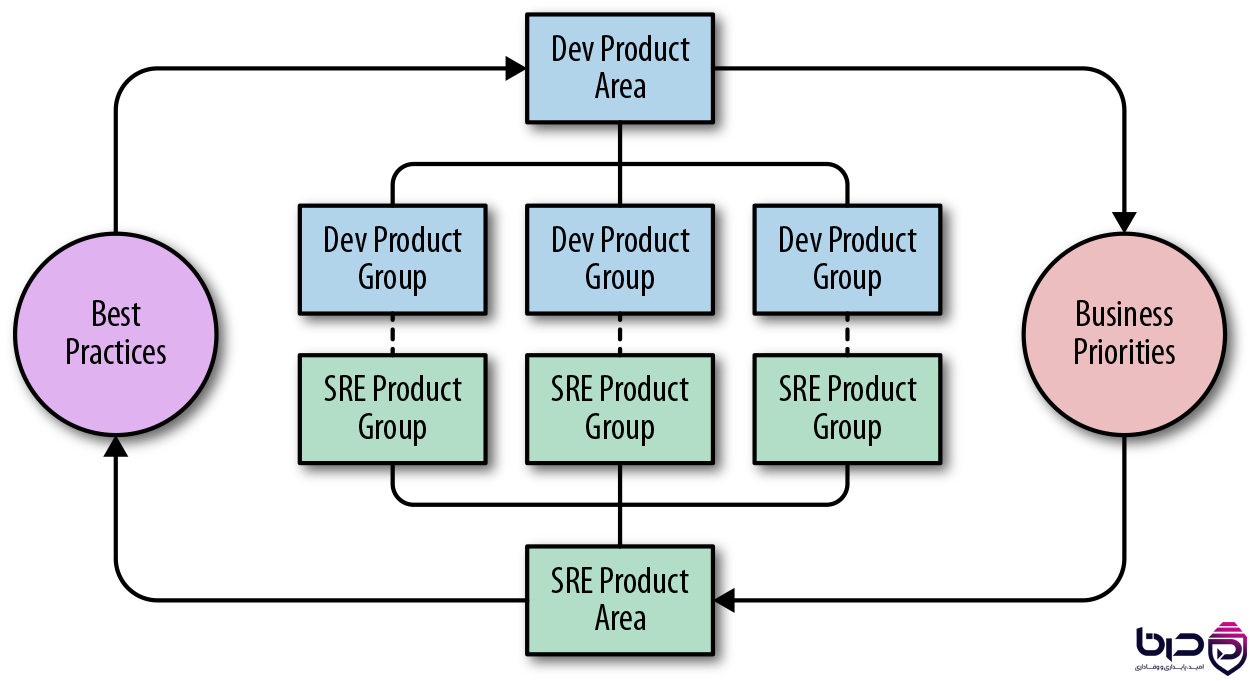
مدل Engagement SRE - Dev Product Area، SRE Product Group و Business Priorities👇
۳. SRE چه چیزهایی را در مرکز توجه قرار میدهد؟
در نگاه رسمی گوگل، SRE بر reliability، measurement، automation و shared understanding تمرکز دارد. در توصیف Google Cloud آمده است که SRE به تیمها کمک میکند بین velocity انتشار ویژگیها و رفتار قابلاعتماد سرویسها تعادل برقرار کنند، و automation را برای کاهش ریسک و آزاد کردن ظرفیت مهندسی برای کارهای استراتژیک بهکار میگیرد.
مثال عملی: فرض کن یک تیم محصول میخواهد هر روز release بدهد. در مدل سنتی، این یعنی فشار بیشتر بر on-call و احتمال بیشتر برای incident. در مدل SRE، همین releaseها با monitoring دقیق، SLO، error budget، canarying و rollout policy مدیریت میشوند تا سرعت توسعه قربانی پایداری نشود. گوگل این موضوع را با مفهوم error budget توضیح میدهد: اگر سرویس از SLO عبور کرد، تیم باید برخی تغییرات را متوقف کند و تمرکز را به reliability برگرداند.
White Box Monitoring در SRE - Load Balancer، API، Website و Game State👇
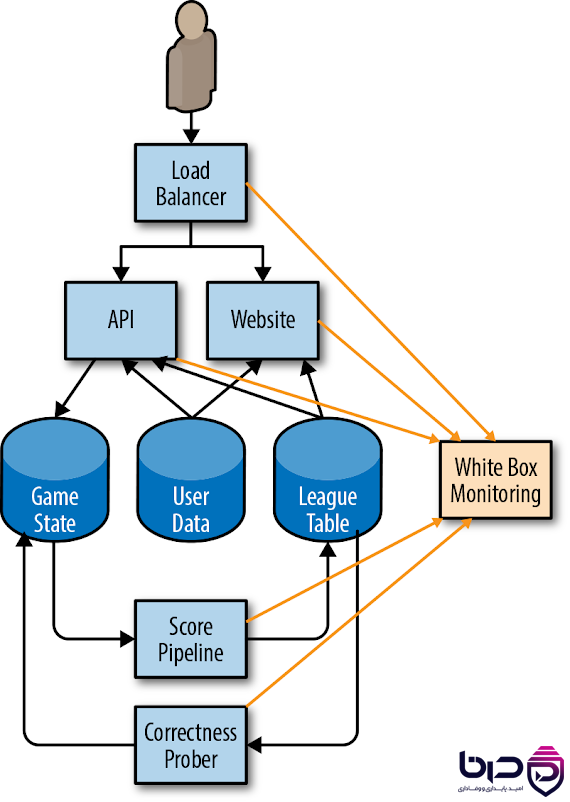
۴. SRE چه تفاوتی با DevOps دارد؟
گوگل SRE را رقیب DevOps نمیداند؛ برعکس، آن را روشی برای عملیاتیکردن اهداف DevOps میبیند. در مقاله رسمی Google Cloud آمده که SRE و DevOps ارزشهای مشترک زیادی دارند و SRE میتواند راهی برای تحقق DevOps objectives باشد. همچنین در SRE book، یک فصل مستقل به «How SRE Relates to DevOps» اختصاص داده شده است، که نشان میدهد این رابطه از ابتدا بخشی از طراحی فکری این discipline بوده است.
تفاوت مهم این است که DevOps بیشتر روی فرهنگ همکاری، automation و شکستن دیوار بین development و operations تأکید دارد، در حالی که SRE همان ارزشها را با ابزارهای دقیقترِ reliability engineering، مثل SLI، SLO، error budget، incident response و postmortem culture وارد عمل میکند. Google Cloud هم در توصیف خود میگوید SRE یک framework برای measurement و prioritization است؛ یعنی SRE بیشتر از آنکه فقط «همکاری» باشد، یک سیستم تصمیمگیری برای production risk است.
DevOps vs SRE - DevOps CICD و Collaboration، SRE Reliability و SLOs👇
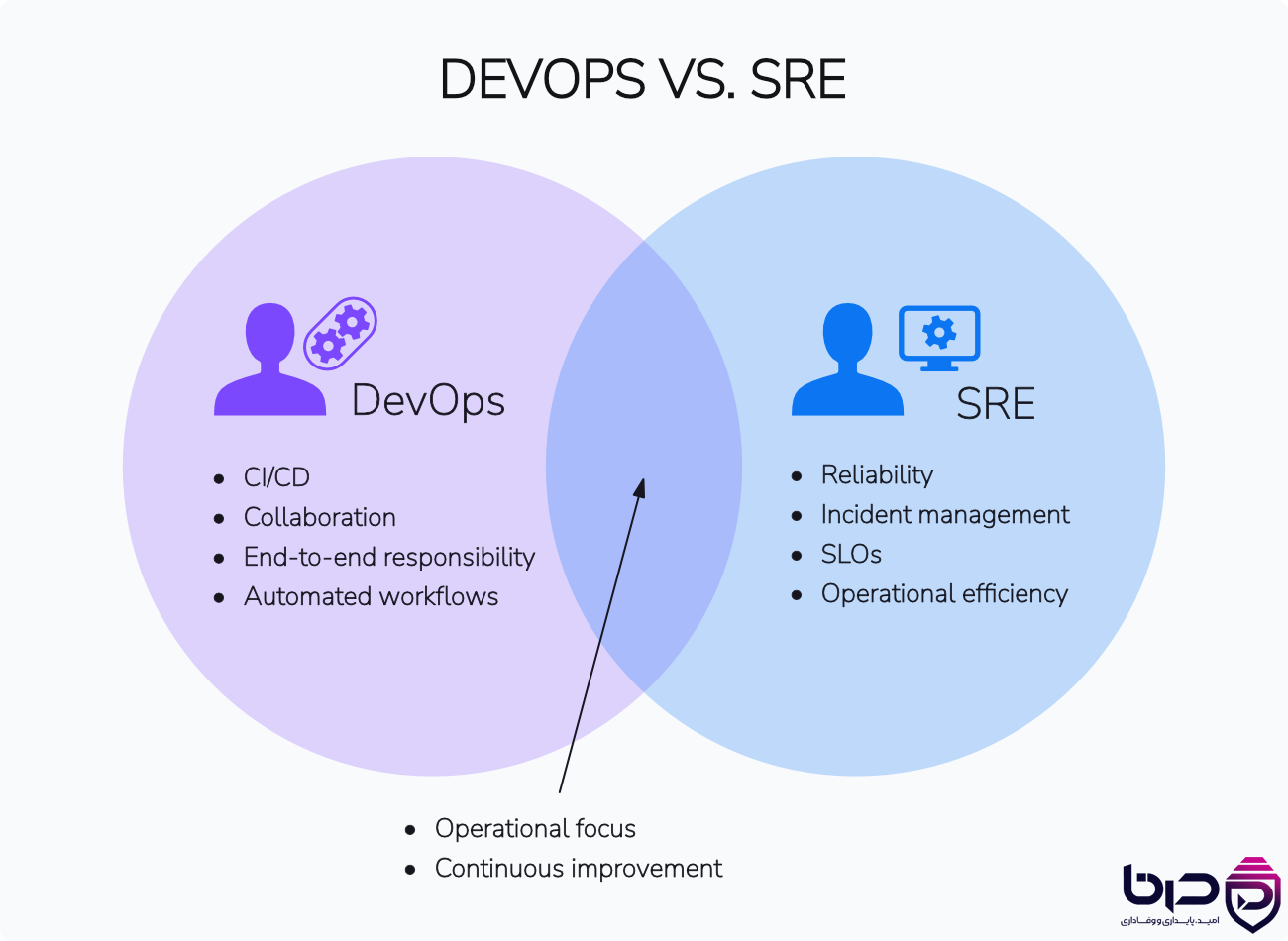
۵. SLI، SLO و SLA در SRE چه نقشی دارند؟
گوگل در توضیح SRE fundamentals میگوید این discipline از این ایده شروع میشود که metrics باید نزدیک به business objectives باشند و برای این کار از سه ابزار کلیدی SLI، SLO و SLA استفاده میشود. به زبان ساده، SLI شاخص اندازهگیری است، SLO هدف داخلی reliability است، و SLA تعهد بیرونی و قراردادی سرویس است.
اگر هنوز با تفاوت SLA، SLO و SLI آشنا نیستید، پیشنهاد میکنیم مقاله «SLA چیست؟ راهنمای کامل Service Level Agreement در خدمات ابری» را بخوانید تا بهتر بفهمید SRE چگونه reliability را از سطح فنی به سطح قراردادی و قابلاندازهگیری تبدیل میکند.
مثال روشن: اگر یک API برای کاربران نهایی مهم است، SLI میتواند درصد درخواستهای موفق یا latency واقعی باشد. SLO ممکن است بگوید 99.9% درخواستها باید موفق باشند. SLA هم تعهد provider به customer است که در صورت برآوردهنشدن آن سطح، جبران مشخصی ارائه میشود. Google Cloud و Google SRE book هر دو نشان میدهند که SRE از همان ابتدا با این سهگانه کار میکند، نه با حدس و احساس.
داشبورد SLO Tracking - FooService سبز، BrokenService قرمز با Trend نزولی👇
۶. Error Budget چیست و چرا قلب SRE محسوب میشود؟
گوگل میگوید error budget ابزار SRE برای balancing میان reliability و pace of innovation است. در policy نمونهای که در SRE book منتشر شده، صراحتاً آمده که اگر سرویس از error budget عبور کند، تغییرات و releases باید متوقف شوند، مگر برای موارد بحرانی مثل security fix یا P01 issues. همان سند توضیح میدهد که error budget برابر ۱ منهای SLO است؛ بنابراین یک سرویس با SLO برابر 99.9%، error budget برابر 0.1% دارد.
این مفهوم در عمل بسیار قدرتمند است، چون بحثهای احساسی را به تصمیمهای دادهمحور تبدیل میکند. بهجای اینکه تیم product بگوید «ما باید feature بدهیم» و تیم reliability بگوید «نه، باید صبر کنیم»، error budget میگوید: تا زمانی که budget باقی مانده، release ادامه دارد؛ اگر budget مصرف شد، اولویت به reliability میرود. گوگل حتی در policy نمونهی خود میگوید این مکانیسم برای تنبیه طراحی نشده، بلکه برای محافظت از customers در برابر SLO misses تکراری و ایجاد انگیزه برای balance میان reliability و feature work است.
مثال
فرض کن یک سرویس در چهار هفته ۱,۰۰۰,۰۰۰ درخواست داشته باشد و SLO آن 99.9% باشد. در این حالت، طبق policy گوگل، error budget آن 0.1% است؛ یعنی حدود ۱,۰۰۰ خطا در آن بازه. اگر یک incident بیش از ۲۰٪ این budget را مصرف کند، team باید postmortem انجام دهد و برای root cause یک P0 action item تعریف کند. این دقیقاً همان جایی است که SRE از واکنش احساسی به کنترل مهندسیشده میرسد.
Alerting بر اساس SLO - Error Rate، Error Rate 5m، Error Rate 60m و Alert Threshold👇
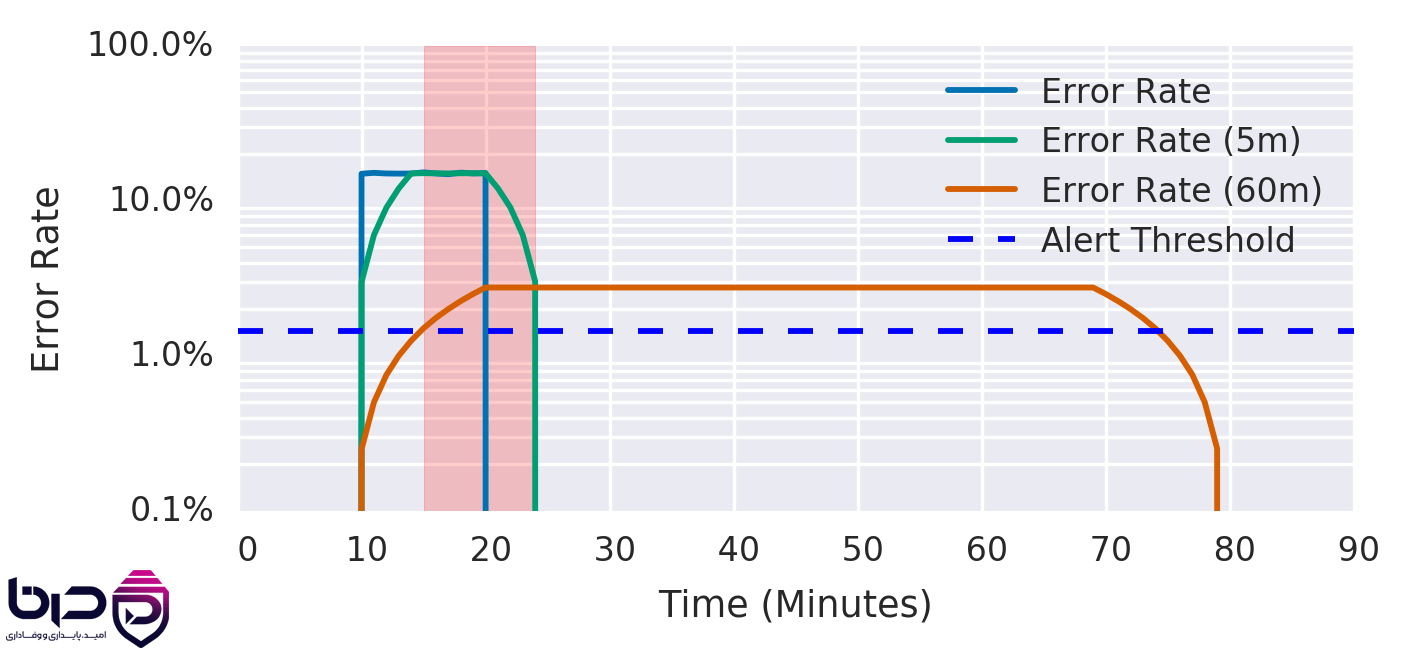
۷. Toil چیست و چرا SRE با آن جنگ دارد؟
گوگل در کتاب SRE «toil» را کاری تعریف میکند که مربوط به running یک production service است، اما manual، repetitive، automatable، tactical، devoid of enduring value و متناسب با رشد سرویس بهصورت خطی بزرگ میشود. به همین دلیل، SRE تلاش میکند تا time spent on operational work را تا حد ممکن پایین بیاورد. در سند رسمی گوگل آمده که هدف advertised این بوده که operational work یا toil کمتر از 50% زمان هر SRE باشد و حداقل نیمی از زمان روی project work صرف شود.
مثال روشن: اگر هر روز یک engineer ساعتها وقتش را صرف restart کردن سرویس، پاکسازی دستی صفها، بررسی مکرر alertهای تکراری یا اجرای scriptهای دستی کند، آن کارها اغلب toil محسوب میشوند. SRE میگوید این نوع کارها باید یا automated شوند یا با redesign از بین بروند، چون human time باید صرف بهبود سیستم شود، نه نگهداری تکراری آن. گوگل حتی میگوید اگر یک human operator در عملیات عادی مجبور باشد به سیستم دست بزند، آن معمولاً نشانهی وجود bug در طراحی است.
تئوری vs واقعیت Automation - Theory Free Time، Reality Debugging و Rethinking👇

۸. SRE در عمل چه کارهایی انجام میدهد؟
فهرست موضوعات رسمی SRE book خودش بهترین سرنخ برای فهم کارهای SRE است. در table of contents این کتاب، فصلهایی مثل Implementing SLOs، Monitoring، Alerting on SLOs، Eliminating Toil، On-Call، Incident Response، Postmortem Culture، Managing Load، Canarying Releases و Identifying and Recovering from Overload دیده میشود. این یعنی SRE فقط monitoring نیست؛ یک چرخهی کامل از پیشگیری، پاسخ، یادگیری و بهبود است.
مثلاً در incident response، هدف فقط خاموش کردن آتش نیست؛ هدف این است که system behavior فهمیده شود، root cause مشخص شود، و service بهصورت ایمن بازیابی شود. در postmortem culture، تمرکز روی سرزنش افراد نیست؛ تمرکز روی یادگیری از failure است. در canarying releases، تغییرات ابتدا روی بخش کوچکی از traffic اعمال میشوند تا risk کاهش یابد. اینها همگی اجزای هستهای SRE هستند، نه فعالیتهای جانبی.
اگر هنوز با معماریهای مدرن تحویل نرمافزار آشنا نیستید، پیشنهاد میکنیم مقاله «CI/CD در ۲۰۲۶؛ از صفر تا دیپلوی بدون قطعی» را بخوانید تا بهتر ببینید SRE چگونه releaseهای پرریسک را با automation و کنترل تدریجی مدیریت میکند.
Monitoring Infrastructure - Binary به AlertManager، Page و Ticket👇
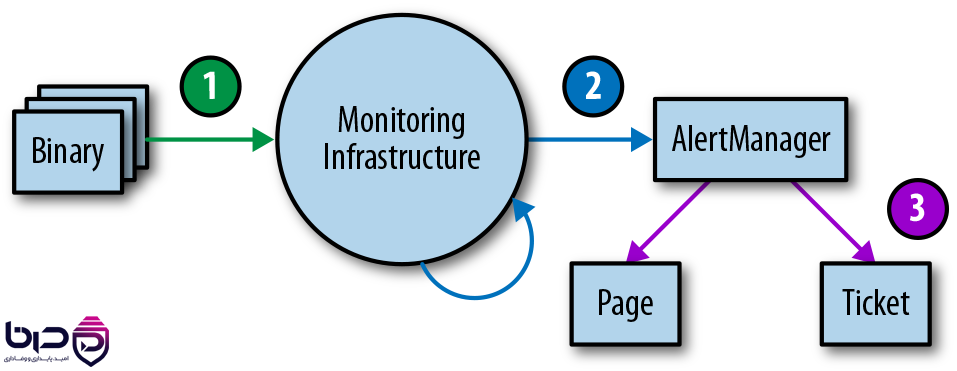
۹. SRE و on-call چه رابطهای دارند؟
SRE بدون on-call قابلتصور نیست، اما on-call در SRE به معنی صرفاً شببیداری نیست. on-call بخشی از سیستم operational ownership است و باید با monitoring خوب، escalation درست، alertهای دقیق و postmortem موثر همراه باشد. SRE book یک فصل مستقل برای on-call و یک فصل مستقل برای incident response دارد که نشان میدهد این دو بخش از core practiceهای SRE هستند.
مثال عملی: اگر یک سرویس وارد شرایط overload شود، on-call باید سریع سیگنال درست را بگیرد، تشخیص دهد آیا مسئله ناشی از افزایش traffic، مشکل dependency، یا bug داخلی است، و سپس از runbook یا automation مناسب استفاده کند. این یعنی on-call در SRE یک مقام صرفاً واکنشی نیست؛ بخشی از یک process مهندسیشده برای مدیریت production risk است.
Google Incident Response - Prepare، Respond و Learn با Communicate👇
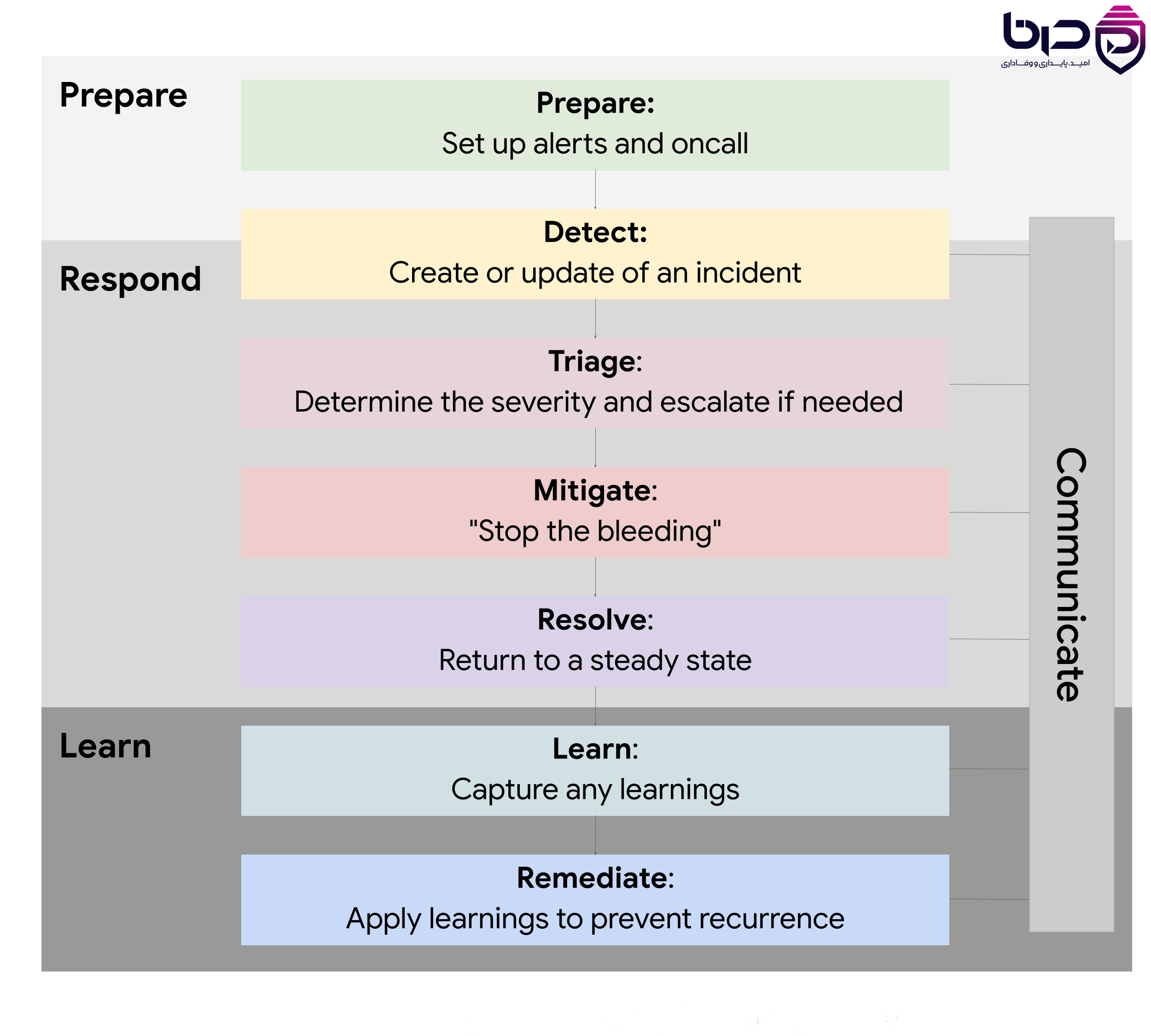
۱۰. چرا monitoring در SRE اینقدر مهم است؟
Google SRE book یک فصل کامل به monitoring distributed systems اختصاص داده است، چون بدون telemetry مناسب، SRE عملاً کور میشود. SRE بر این اصل تکیه دارد که metrics باید به business objectives نزدیک باشند و alarms باید بر اساس SLOها طراحی شوند، نه صرفاً بر اساس noise یا شاخصهای بیربط.
مثال: اگر یک سرویس فقط CPU را مانیتور کند، ممکن است در ظاهر سالم بهنظر برسد، اما از دید کاربر latency بالا داشته باشد یا error rate افزایش پیدا کرده باشد. SRE به جای تکیه بر metricهای سطح ماشین، روی signalهایی تمرکز میکند که مستقیماً به user-visible reliability مربوطاند. به همین دلیل، SLI و SLO در SRE هستهی monitoring design هستند.
اگر هنوز با observability و نقش آن در monitoring سیستمهای توزیعشده آشنا نیستید، پیشنهاد میکنیم ابتدا مقاله «Prometheus و Grafana چیست؟ راهنمای کامل Observability در Cloud-Native» را مطالعه کنید تا بهتر متوجه شوید SRE چرا بدون metric و trace عملاً کور میشود.
Four Golden Signals - Latency، Traffic، Errors و Saturation👇
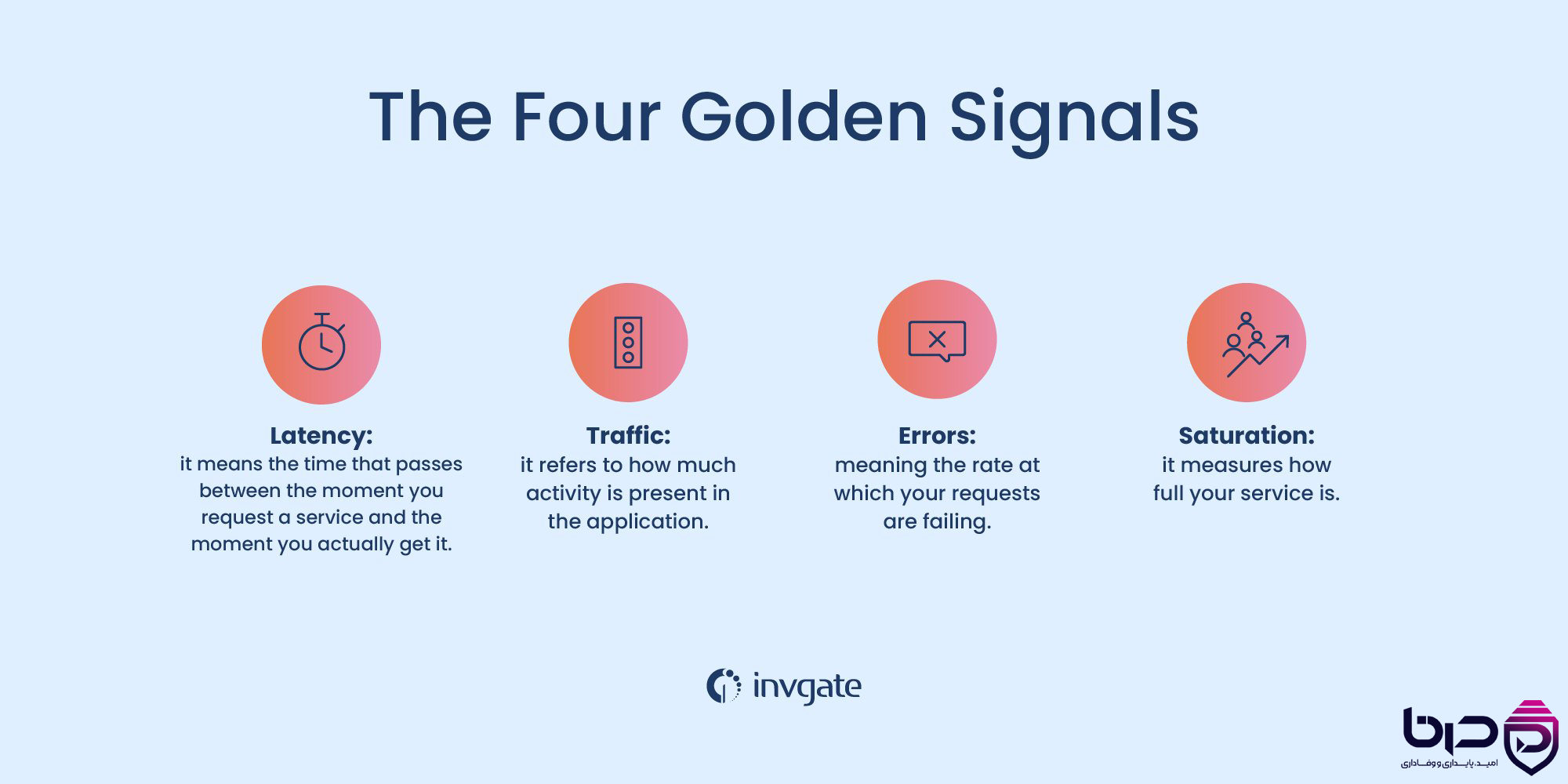
۱۱. SRE و automation چرا با هم گره خوردهاند؟
گوگل در شرح SRE صریحاً میگوید این discipline بر automation تأکید دارد تا risk کاهش یابد و engineering capacity برای strategic work آزاد شود. در سند toil هم تأکید شده که کارهای دستی، تکراری و قابلautomation باید تا حد ممکن از دوش انسان برداشته شوند. این نگاه در واقع ستون اصلی SRE است: اگر عملیاتی میتواند توسط ماشین انجام شود، انسان باید انرژی خود را برای تصمیمهایی بگذارد که واقعاً به judgment نیاز دارند.
مثال عملی: بهجای اینکه مهندس هر بار deployment را دستی بررسی کند، pipeline باید health checks، rollback plan، canary checks و approval gates را خودکار انجام دهد. بهجای اینکه تیم بهصورت دستی capacity را حدس بزند، باید بر اساس metrics و load trends تصمیمگیری کند. این همان جایی است که automation نه یک مزیت جانبی، بلکه شرط بقا در SRE میشود.
Automation Workflow - Memory Error Alert، Engineer Evaluation و HWops Repair👇
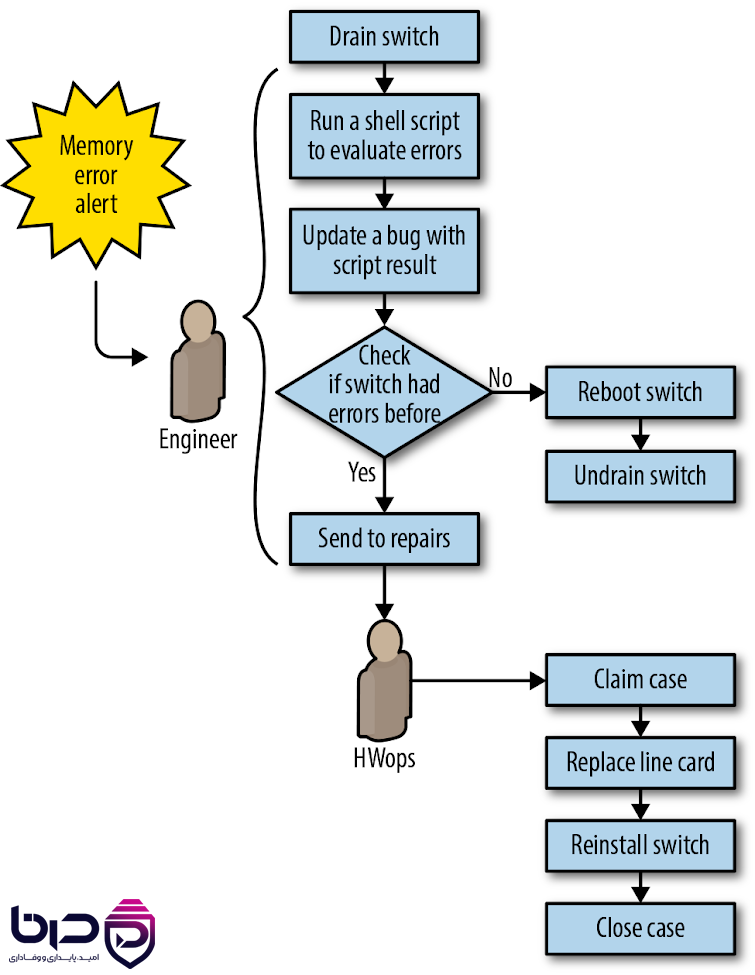
۱۲. SRE چرا برای business هم مهم است؟
Google Cloud در مقالهی مربوط به SRE و DevOps میگوید reliability فقط یک دغدغهی فنی نیست؛ وقتی کاربران نتوانند به اپلیکیشن دسترسی داشته باشند یا سرویس کند و غیرمنتظره رفتار کند، ارزش مورد انتظار خود را دریافت نمیکنند و این موضوع میتواند مستقیماً روی revenue، reputation و user loyalty اثر بگذارد. به همین دلیل، گوگل reliability را «مهمترین feature هر system» توصیف میکند.
مثال: یک فروشگاه آنلاین اگر در زمان کمپین فروش، latency یا error rate بالایی داشته باشد، فقط از نظر فنی دچار مشکل نشده است؛ نرخ تبدیل، اعتماد مشتری و درآمد واقعی هم آسیب میبیند. SRE با تعریف SLO، error budget و incident discipline کمک میکند reliability به زبان business ترجمه شود و از سطح «مشکل فنی» به سطح «اثر تجاری» برسد.
Postmortem Metrics - Incident Count، Detection، Duration و Resolution در طول سال👇
۱۳. SRE در سازمانها چگونه adopt میشود؟
گوگل تأکید میکند که SRE یک learning discipline است و adoption آن باید تدریجی و iterative باشد، نه یک تغییر ناگهانی و شعاری. در مقالهی رسمی Google Cloud آمده که موفقیت در SRE نیازمند starting small و iterative approach است. این نگاه بسیار مهم است، چون SRE را نمیتوان با نصب چند ابزار یا عوض کردن عنوان شغلی پیاده کرد.
مثال: یک تیم ممکن است ابتدا فقط با تعریف چند SLO شروع کند، بعد monitoring و alerting را به آن متصل کند، سپس runbook و incident response را اضافه کند، و در مرحله بعد error budget و postmortem culture را وارد کند. این مسیر تدریجی بسیار سالمتر از این است که یک سازمان بدون آمادگی فرهنگی و فنی، یکباره خود را SRE-mature اعلام کند.
۱۴. SRE و postmortem culture چه نسبتی دارند؟
در SRE book یک فصل مستقل به Postmortem Culture: Learning from Failure اختصاص داده شده است. این خودش پیام مهمی دارد: failure در SRE چیزی نیست که صرفاً باید پنهان یا مقصرجویی شود؛ failure منبع learning است. گوگل در error budget policy خود هم تصریح میکند که اگر یک incident سهم قابلتوجهی از budget را مصرف کند، باید postmortem انجام شود و action item مشخصی برای root cause تعریف شود.
مثال: اگر deployment جدید باعث outage شود، SRE mature نمیگوید «چه کسی مقصر بود؟» بلکه میپرسد: چرا canary نگرفت؟ چرا alert دیر آمد؟ چرا rollback سریع نبود؟ چرا dependency hard بود؟ این نوع سؤالها سیستم را بهتر میکنند، نه اینکه فقط افراد را بازخواست کنند. همین نگاه، فرهنگ blameless learning را به یکی از نشانههای اصلی SRE تبدیل کرده است.
۱۵. SRE برای چه نوع سازمانهایی مناسب است؟
SRE بهطور ویژه برای سازمانهایی مفید است که production systems پیچیده، release frequency بالا، traffic زیاد، dependencies متعدد و نیاز جدی به reliability دارند. Google Cloud در توصیف خود نشان میدهد که SRE برای balancing feature velocity و predictable behavior طراحی شده و از طریق automation و measurement به تیمها کمک میکند. همچنین Google گزارش کرده که SRE بهصورت گسترده در صنعت پذیرفته شده و در survey DORA بیش از نیمی از پاسخدهندگان بخشی از SRE practices را بهکار میبرند.
اگر هنوز با امنسازی لایهی زیرساخت و کاهش سطح حمله آشنا نیستید، پیشنهاد میکنیم مقاله «OS Hardening چیست؟ راهنمای جامع امنسازی سیستمعامل در ۲۰۲۶» را مطالعه کنید تا بهتر متوجه شوید reliability فقط به monitoring و error budget محدود نمیشود.
مثال: شرکتهای SaaS، پلتفرمهای تجارت الکترونیک، خدمات مالی، سرویسهای streaming، زیرساختهای cloud platform و تیمهای platform engineering بیشترین بهره را از SRE میبرند، چون failure در این محیطها هم پرهزینه است و هم اجتنابناپذیر. در چنین شرایطی، SRE به جای واکنشهای پراکنده، یک operating model منظم فراهم میکند.
Load Balancing در SRE - Maglev، Nginx و Kubernetes Cluster👇
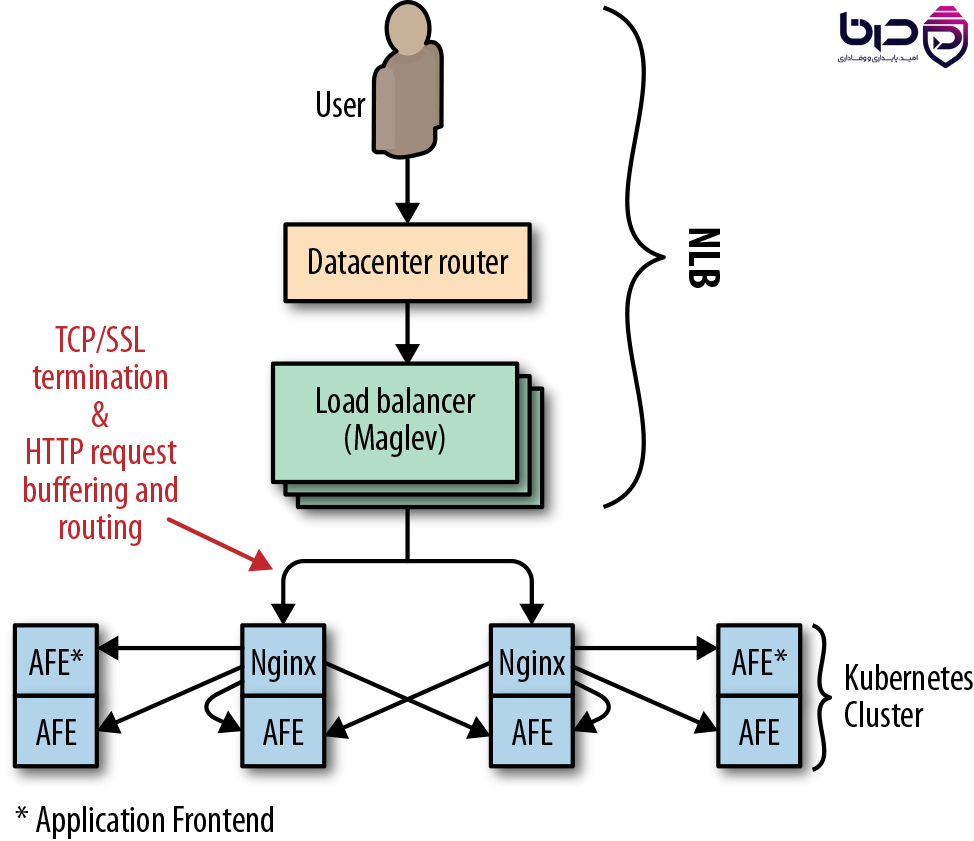
16. سوالات متداول FAQ Schema
SRE دقیقاً چه کاری انجام میدهد؟
SRE با استفاده از اصول مهندسی نرمافزار، reliability، availability، scalability و operational excellence سیستمهای production را مدیریت میکند. Google Cloud آن را یک job function، mindset و set of engineering practices معرفی میکند.
تفاوت SRE و DevOps چیست؟
DevOps بیشتر بر همکاری، automation و فرهنگ مشترک تمرکز دارد، در حالی که SRE همین اهداف را با ابزارهای دقیق reliability مثل SLI، SLO، error budget، incident response و postmortem عملیاتی میکند. Google Cloud میگوید این دو همپوشانی دارند و SRE میتواند DevOps را محقق کند.
چرا error budget در SRE مهم است؟
چون به تیم کمک میکند میان feature velocity و reliability تعادل برقرار کند. اگر error budget مصرف شود، طبق policy گوگل تغییرات باید متوقف شوند تا تمرکز روی reliability برگردد.
toil در SRE یعنی چه؟
Toil کار دستی، تکراری، قابلautomation، تاکتیکی و بدون ارزش پایدار است که با رشد سرویس بهصورت خطی زیاد میشود. گوگل هدف داشته operational work هر SRE کمتر از 50% زمان او باشد. sre.google7
آیا SRE فقط برای شرکتهای خیلی بزرگ است؟
خیر. هر سازمانی که production systems پیچیده، releaseهای مکرر، یا نیاز جدی به reliability داشته باشد میتواند از SRE بهره ببرد. Google Cloud هم SRE را رویکردی عمومی و قابلadopt میداند، نه صرفاً ویژهی غولهای فناوری.
17. نتیجهگیری
- SRE در نهایت یعنی تبدیل reliability به یک مسئلهی مهندسی، نه یک کار اتفاقی. گوگل SRE را job function، mindset و مجموعهای از engineering practices میداند که برای اجرای reliable production systems بهکار میرود. در این مدل، monitoring، SLO، error budget، toil reduction، on-call، incident response، postmortem، automation و canary releases همگی اجزای یک سیستم واحدند، نه مفاهیم جدا از هم.
- اگر بخواهیم خیلی دقیق جمعبندی کنیم، SRE پاسخی است به یک واقعیت روشن: هرچه سیستمها بزرگتر و پیچیدهتر میشوند، reliability را نمیتوان با امید، شانس یا heroism حفظ کرد. باید آن را اندازه گرفت، مدل کرد، محدود کرد، خودکار ساخت و از failure یاد گرفت. SRE دقیقاً همین کار را انجام میدهد؛ و به همین دلیل است که امروز یکی از مهمترین ستونهای reliability engineering در جهان مدرن نرمافزار بهشمار میآید.