در دنیای سنتی فناوری اطلاعات، مانیتورینگ اغلب به معنای بررسی روشن یا خاموش بودن سرور، میزان پر بودن دیسک، یا مقدار مصرف CPU بود. اما در جهان امروز، جایی که سیستمها از دهها یا صدها میکروسرویس، صف پیام، کلاسترهای Kubernetes، محیطهای چندابری، و معماریهای eventdriven تشکیل شدهاند، چنین نگاه سادهای دیگر کافی نیست.
وقتی یک درخواست از سمت کاربر وارد سیستم میشود، ممکن است از API Gateway، سرویس احراز هویت، سرویس سفارش، صف Kafka، پایگاهداده، کش Redis، سرویس پرداخت، و حتی چندین سرویس خارجی عبور کند. در چنین ساختاری، اگر فقط بدانیم «سرویس بالا است یا پایین»، عملاً چیزی از رفتار واقعی سیستم نمیفهمیم. اینجاست که مفهوم Observability وارد میشود؛ مفهومی که هدف آن فقط «دیدن» نیست، بلکه درک عمیق رفتار سیستم از روی خروجیهای آن است.
مشاهدهپذیری در عمل بر سه ستون اصلی استوار است: Metrics، Logs و Traces. اما در میان این سه، متریکها همچنان نقش ستون فقرات را دارند؛ زیرا سریع، ساختیافته، قابل هشداردهی، و مناسب تحلیلهای زمانی هستند. در همین نقطه است که دو ابزار متنباز و بسیار مهم از اکوسیستم CNCF یعنی Prometheus و Grafana به مرکز صحنه میآیند. Prometheus موتور جمعآوری و ذخیرهسازی متریک است و Grafana لایهی بصریسازی، تحلیل و داشبوردسازی را بر عهده دارد.
این مقاله، فقط معرفی این دو ابزار نیست؛ بلکه یک کالبدشکافی عمیق از معماری داخلی، مدل داده، روشهای جمعآوری، کوئرینویسی پیشرفته، طراحی داشبورد، alerting، مقیاسپذیری سازمانی، و الگوی استقرار آنها در محیطهای productionlevel و enterprisegrade است.
۱. کالبدشکافی موتور Prometheus: فراتر از یک دیتابیس ساده
Prometheus فقط یک ابزار برای نمایش چند نمودار نیست. در واقع، Prometheus یک سیستم کامل متریکمحور است که از چهار جزء کلیدی تشکیل میشود: جمعآوری داده، ذخیرهسازی سریزمانی، زبان کوئری، و alerting. هر کدام از این لایهها برای حل یک مسئلهی خاص در دنیای distributed systems طراحی شدهاند.
در رویکرد DevSecOps، مانیتورینگ و alerting نقش مهمی در شناسایی سریع تهدیدات دارند. ما در مقاله «DevSecOps چیست ؟» کامل به این رویکرد امنیت در دواپس اشاره کردیم .
الف) معماری Pull در برابر Push: فلسفهای که مقیاسپذیری را ممکن کرد
بسیاری از سیستمهای مانیتورینگ سنتی بر پایه Push ساخته شدهاند؛ یعنی Agentهای نصبشده روی سرورها، متریکها را بهصورت مداوم به سمت یک سرور مرکزی ارسال میکنند. این مدل در ظاهر ساده است، اما در مقیاس بزرگ مشکلات جدی ایجاد میکند: فشار ناگهانی روی شبکه، تجمع burstهای داده، وابستگی شدید به Agentها، و سختی در تشخیص اینکه آیا عدم دریافت داده ناشی از نبود بار کاری است یا از کار افتادن خود سیستم.
Prometheus بر خلاف این رویکرد، از مدل PullBased Scraping استفاده میکند. یعنی Prometheus بهصورت دورهای، معمولاً هر ۱۵ ثانیه یا هر بازهای که تعریف شده، خودش به مقصدهای از پیش مشخصشده مراجعه میکند و endpoint متریک، معمولاً `/metrics`، را scrape میکند. این طراحی چند مزیت مهم دارد:
1. کنترل مرکزی بر چرخه جمعآوری
سرور Prometheus تصمیم میگیرد چه زمانی، از چه چیزی، و با چه تناوبی داده بخواند.
2. کشف سریع خرابی
اگر scrape موفق نشود، خود این failure به یک سیگنال قابل تحلیل تبدیل میشود.
3. سادگی معماری سمت سرویس
سرویس فقط باید endpoint متریک را expose کند؛ نه اینکه منطق ارسال، retry، batching، یا routing را در خود پیادهسازی کند.
4. تناسب با service discovery پویا
در محیطهایی مثل Kubernetes، که Podها ممکن است در چند ثانیه ساخته یا نابود شوند، مدل Pull بههمراه Service Discovery بسیار کارآمدتر از معماریهای ثابت است.
البته این مدل در سطح enterprise نیز بهصورت گسترده قابل تنظیم است. میتوان scrape intervalهای مختلف برای jobهای مختلف تعریف کرد، timeoutهای جداگانه گذاشت، relabeling انجام داد، و حتی هدفها را از طریق Kubernetes API، Consul، EC2 SD، Azure SD، فایلهای دینامیک، یا static configها دریافت کرد.
ب) موتور ذخیرهسازی TSDB: قلب حافظه سریزمانی Prometheus
Prometheus دادهها را در یک TimeSeries Database (TSDB) داخلی ذخیره میکند. هر سری زمانی در Prometheus بر اساس ترکیب سه جزء اصلی تعریف میشود:
نام متریک ، مجموعه labelها ، timestamp و value
برای مثال، متریک زیر:
`http_requests_total{method="GET", status="500", instance="10.0.1.12:8080"}`در ظاهر فقط یک عدد است، اما در واقع یک سری زمانی است که به شکل مداوم در طول زمان ثبت میشود. این مدل داده، اساس تمام تحلیلهای بعدی را تشکیل میدهد.
ساختار ذخیرهسازی داخلی
TSDB پرومتئوس بهصورت فایلمحور و بسیار بهینه طراحی شده است. دادهها ابتدا در memory head block نگهداری میشوند، سپس با استفاده از WAL (WriteAhead Log) پایدار میشوند، و بعد از تکمیل شدن بلوکها به دیسک منتقل میشوند. این مکانیزم چند مزیت مهم دارد:
- جلوگیری از از دست رفتن داده در صورت crash ناگهانی
- بازیابی سریع پس از restart
- فشردهسازی ساختارمند دادهها
- کاهش چشمگیر I/O بیمورد
- WAL و نقش آن در پایداری
WriteAhead Log به Prometheus اجازه میدهد قبل از اینکه دادهها به ساختارهای اصلی TSDB نوشته شوند، نسخهای از آنها را در یک log appendonly ثبت کند. در صورت خاموشی ناگهانی، Prometheus میتواند از این log برای بازسازی وضعیت اخیر استفاده کند. این موضوع برای محیطهای production حیاتی است، زیرا از نظر عملی، حتی چند دقیقه از دست رفتن متریکها هم میتواند مانع تحلیل root cause شود.
بلوکها، Compaction و Retention
Prometheus دادهها را به بلوکهای زمانی تقسیم میکند و سپس آنها را در فرآیند compaction فشرده میسازد. این کار هم بهرهوری ذخیرهسازی را بالا میبرد و هم جستوجوی بازههای زمانی را سریعتر میکند.
سیاست retention نیز تعیین میکند دادهها تا چه مدت در local storage نگهداری شوند. در نصبهای کوچک ممکن است چند روز یا چند هفته کافی باشد، اما در محیطهای enterprise معمولاً Prometheus فقط نقش local scraping layer را دارد و ذخیرهسازی بلندمدت به لایههای بالاتری مثل Thanos، Cortex، Mimir یا remote storageها واگذار میشود.
چرا Prometheus برای متریکها عالی است؟
Prometheus برای متریکهای عددی و سریزمانی طراحی شده، نه برای دادههای transactionoriented یا relational. همین تخصصگرایی باعث شده در latency پایین، تحلیل سریزمانی، و مدل alerting، عملکرد فوقالعادهای داشته باشد. اما باید توجه داشت که این تخصصگرایی به این معناست که Prometheus برای همه نوع داده بهترین گزینه نیست؛ مثلاً برای جستوجوی متنی کامل، لاگهای خام، یا تراکنشهای پیچیده، باید از ابزارهای مکمل استفاده شود.
ج) Service Discovery: کشف خودکار در جهانی که دائماً در حال تغییر است
در معماریهای سنتی، IP سرورها ثابت بود و ابزار مانیتورینگ با لیستی از hosts از پیش تعریفشده کار میکرد. اما در معماری CloudNative، چنین چیزی عملاً منسوخ شده است. Podها در Kubernetes میتوانند هر لحظه recreate شوند، nodeها scale up/down شوند، و سرویسها پشت load balancerها جابهجا شوند.
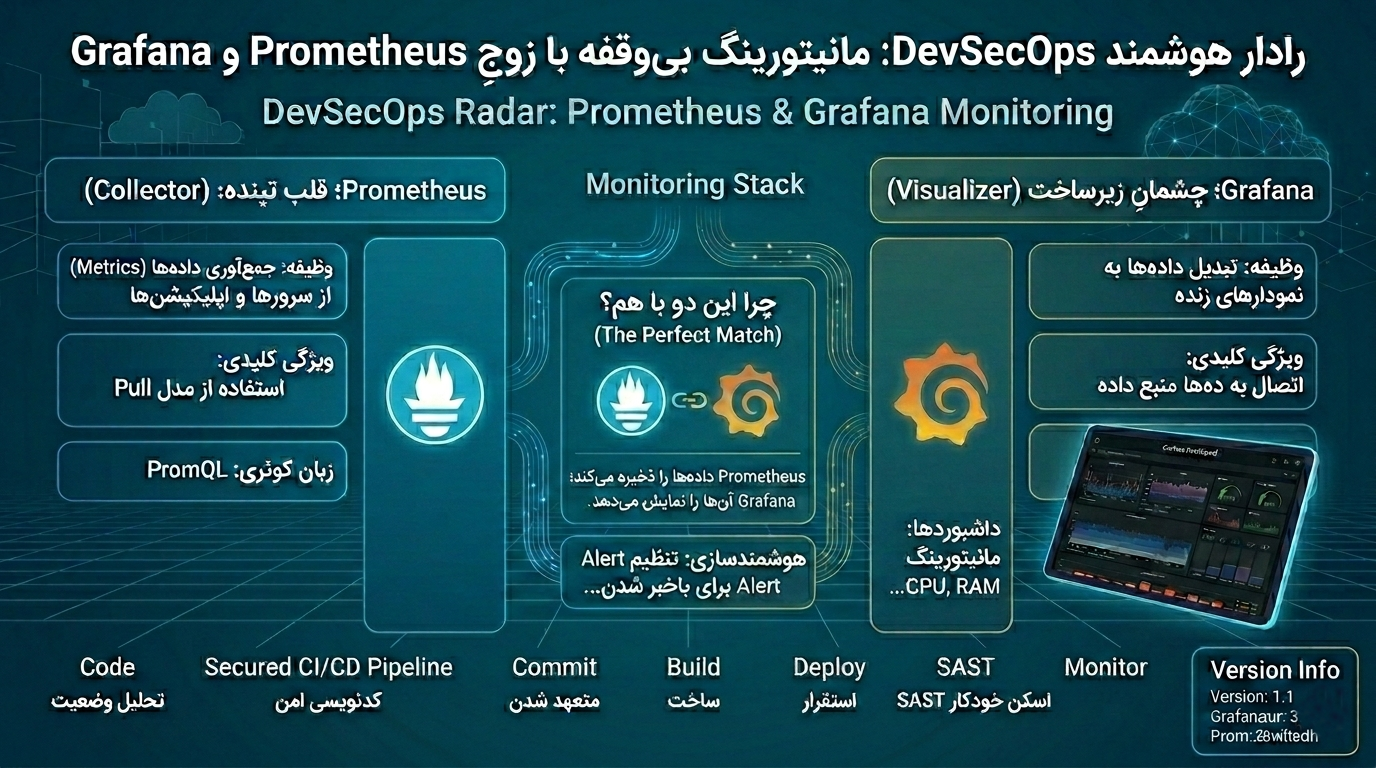
Prometheus با Service Discovery این مشکل را حل میکند. او میتواند مقصدها را از منابع مختلف کشف کند، از جمله:
- Kubernetes API
Consul
AWS EC2
Azure VM
GCE
فایلهای dynamic target
DNSbased discovery
این یعنی Prometheus بهجای تکیه بر IP ثابت، از هویت منطقی سرویس پیروی میکند. این موضوع در محیطهای microservice و multitenant بسیار حیاتی است.
د) Relabeling: کنترل دقیق روی هدفها و labels
یکی از قابلیتهای بسیار مهم و اغلب دستکمگرفتهشده در Prometheus، relabeling است. Relabeling به شما اجازه میدهد labels را قبل از scrape، بعد از discovery، یا حتی بعد از ingestion تغییر دهید. با relabeling میتوان:
مقصدهای ناخواسته را حذف کرد .
labelهای استاندارد یا سفارشی اضافه کرد .
namespace، cluster، team، environment یا region را به دادهها تزریق کرد .
سریهای زمانی پرهزینه و غیرضروری را drop کرد .
در مقیاس بزرگ، relabeling تفاوت بین یک سیستم قابل مدیریت و یک سیستم انفجاری است.
کشف خودکار Podها و سرویسها در Kubernetes توسط Prometheus API.png👇
۲. صادرات داده: ارتش Exporterها و ابزار دقیق (Instrumentation)
Prometheus ذاتاً برنامهها را نمیفهمد؛ او فقط میداند چگونه به endpointهایی با فرمت استاندارد خودش مراجعه کند و داده بخواند. بنابراین برای اینکه سیستمها با Prometheus صحبت کنند، باید متریکها به شکلی ساختیافته expose شوند. این کار از طریق Exporters و Instrumentation مستقیم انجام میشود.
۱. استفاده از Exporterهای استاندارد
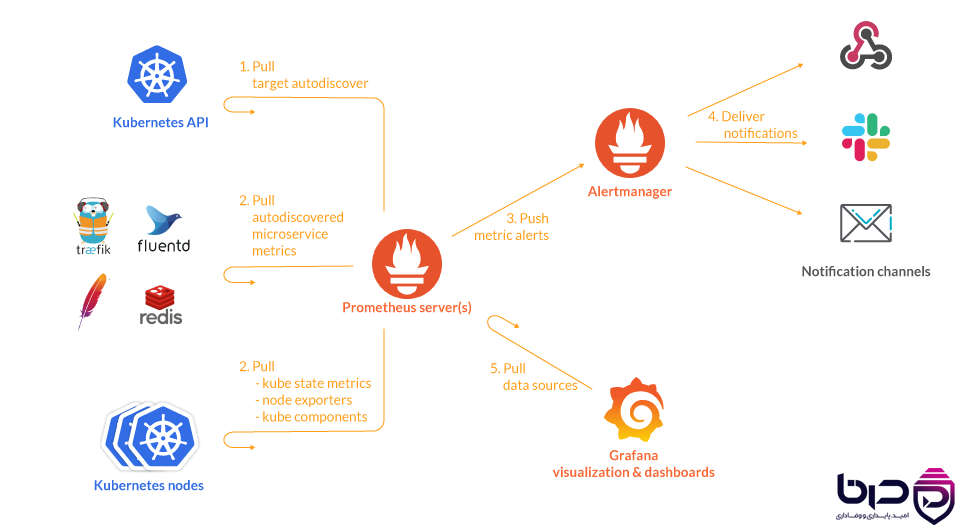
Node Exporter
Node Exporter یکی از بنیادیترین اجزای اکوسیستم Prometheus است. این ابزار روی سرورهای لینوکسی اجرا میشود و مجموعهای وسیع از متریکهای سطح سیستمعامل و kernel را استخراج میکند، از جمله:
1.1. مصرف CPU در حالتهای مختلف
1.2. load average
1.3. وضعیت حافظه و swap
1.4. وضعیت filesystem
1.5. disk I/O
1.6. throughput شبکه
1.7. interruptها و context switchها
1.8. filesystem mountها
1.9. entropy و برخی متریکهای خاص کرنل
Node Exporter معمولاً بهعنوان دید «زیرساخت خام» به سیستم شناخته میشود. اگر application level همهچیز را سالم نشان دهد ولی node دچار saturation شده باشد، بدون Node Exporter تشخیص این مشکل دشوار خواهد بود.
در پروژههای Dockerized، استفاده از ابزارهای مانیتورینگ مانند Prometheus ضروری است. ما مقاله ای آماده کردیم تحت عنوان «7 اشتباه مرگبار در داکرایز کردن پروژه ها» با رعایت کردن این نکات دیگه اشتباهات مرسوم رو تکرار نکنید .
Blackbox Exporter
Blackbox Exporter از بیرون به سرویس نگاه میکند، نه از داخل آن. این ابزار برای سنجش availability و رفتار خارجی سرویس طراحی شده است. از آن میتوان برای موارد زیر استفاده کرد:
1.1. HTTP probe
1.2. HTTPS probe
1.3. TCP probe
1.4. ICMP ping
1.5. DNS probe
1.6. بررسی گواهی SSL/TLS
1.7. ارزیابی redirectها
1.8. بررسی زمان پاسخ واقعی از دید کاربر
این نگاه خارجی برای تشخیص تفاوت بین «سرویس بالا است» و «سرویس از دید کاربر واقعاً قابل استفاده است» بسیار مهم است.
KubeStateMetrics
KubeStateMetrics بر خلاف Node Exporter که وضعیت سیستمعامل را میسنجد، وضعیت اشیای Kubernetes را expose میکند. بهعبارت دیگر، این ابزار state objectهای Kubernetes مانند Deployment، ReplicaSet، Pod، DaemonSet، Job، HPA و … را به متریک تبدیل میکند.
این ابزار برای فهمیدن وضعیت منطقی کلاستر حیاتی است، چون گاهی node سالم است اما Deployment در وضعیت CrashLoopBackOff یا Pending قرار دارد. این دو سطح باید جداگانه مانیتور شوند.
سایر Exporterها
در اکوسیستم Prometheus exporterهای دیگری نیز وجود دارند، مانند:
1.1. MySQL Exporter
1.2. PostgreSQL Exporter
1.3. Redis Exporter
1.4. Nginx Exporter
1.5. HAProxy Exporter
1.6. RabbitMQ Exporter
1.7. Kafka Exporter
1.8. Elasticsearch Exporter
1.9. Windows Exporter
این تنوع باعث میشود تقریباً هر چیزی که endpoint متریک داشته باشد، قابل مانیتور باشد.
۲. Instrumentation مستقیم در کد برنامه
گاهی exporter عمومی کافی نیست. در این حالت، تیم توسعه باید خود اپلیکیشن را instrument کند. Prometheus برای زبانهای رایج، client libraryهای رسمی یا معتبر دارد؛ مانند Python، Go، Java، Node.js، Ruby، PHP، C و غیره.
سه نوع متریک اصلی در instrumentation
Prometheus سه الگوی مهم برای متریکها تعریف میکند:
Counter
فقط افزایش پیدا میکند و برای شمارش رویدادها مناسب است.
مثال: تعداد درخواستها، تعداد خطاها، تعداد پرداختها.
Gauge
میتواند بالا و پایین برود.
مثال: تعداد کاربران آنلاین، مقدار حافظه مصرفشده، صف فعال.
Histogram
برای توزیع مقادیر و محاسبه percentileها استفاده میشود.
مثال: latency درخواستها، زمان پاسخ دیتابیس، سایز payloadها.
Summary
برای quantileهای محلی و محاسبات آماری درونسرویس استفاده میشود، هرچند در محیطهای distributed باید با دقت استفاده شود.
مثال کاربردی instrumentation
فرض کنید در سرویس پرداخت، متریک زیر تعریف میشود:
`payment_processing_seconds`
هر بار که یک تراکنش کامل میشود، زمان پردازش ثبت میشود. حالا Prometheus میتواند تشخیص دهد که:
latency نسخه جدید نسبت به نسخه قبلی افزایش یافته است
درصد تراکنشهای کند در ساعات اوج ترافیک بیشتر میشود
یک dependency خاص، مانند بانک یا سرویس OTP، باعث کندی شده است
در کدام region یا cluster مشکل بیشتر رخ میدهد
این همان جایی است که telemetry از یک عدد ساده به یک ابزار تصمیمسازی تبدیل میشود.
۳. اصول طراحی متریک خوب
یک metric خوب باید چند ویژگی داشته باشد:
معنای روشن و پایدار داشته باشد
با labelهای محدود اما مفید طراحی شود
از cardinality انفجاری جلوگیری کند
برای alerting و dashboarding قابل استفاده باشد
با SLOها و business KPIها قابل اتصال باشد
اشتباه رایج این است که توسعهدهندگان متریکی با labelهای بسیار زیاد میسازند، مثلاً `user_id` یا `request_id` را بهعنوان label قرار میدهند. این کار باعث high cardinality میشود و میتواند بار سنگینی روی Prometheus ایجاد کند. در طراحی حرفهای observability، cardinality یک موضوع بسیار جدی است.
معماری Node Exporter جمعآوری متریکهای سیستمعامل و ارائه به Prometheus.png👇
۳. جادوی تاریک PromQL: زبانی برای تحلیل زمان
اگر Prometheus قلب سیستم observability باشد، PromQL مغز تحلیلی آن است. PromQL فقط یک زبان کوئری نیست؛ یک زبان مدلسازی رفتار سریزمانی است. برخلاف SQL که روی جدولهای relation کار میکند، PromQL روی data points در بازههای زمانی مشخص کار میکند.
الف) مفاهیم پایه در PromQL
PromQL با نوعهای مختلف selector و function کار میکند. مهمترین مفاهیم آن عبارتند از:
Instant vector
Range vector
Scalar
String
با این ابزارها، میتوان رفتار گذشته را بررسی کرد، روندها را تشخیص داد، نرخها را محاسبه کرد، anomalyها را پیدا کرد، و alertهای دقیق ساخت.
ب) نرخ خطا و throughput
یکی از مهمترین استفادههای PromQL محاسبه نرخ درخواستها و خطاهاست. بهجای شمردن raw counterها، باید از تابع `rate()` استفاده کرد تا نرخ تغییرات در یک بازه زمانی مشخص محاسبه شود.
مثال:
promql
rate(http_requests_total{status="500"}[5m])این کوئری به شما میگوید در پنج دقیقه اخیر، نرخ خطاهای ۵۰۰ چقدر بوده است. اما در عمل معمولاً از این کوئری در کنار نرخ کل درخواستها استفاده میشود تا error ratio محاسبه شود.
ج) محاسبه درصد خطا
promql
sum(rate(http_requests_total{status=~"5.."}[5m]))
/
sum(rate(http_requests_total[5m]))این کوئری یکی از پایهایترین ابزارها برای SLI و error budget است. اگر سهم خطا از یک آستانه مشخص بالاتر برود، میتوان alert فعال کرد یا rollout را متوقف نمود.
د) محاسبه latency و صدکها
یکی از پیچیدهترین و مهمترین بخشهای observability، تحلیل latency است. میانگین latency همیشه گمراهکننده است، چون چند request بسیار سریع میتوانند یک spike شدید را پنهان کنند. به همین دلیل percentileها اهمیت دارند.
برای histogramها، معمولاً از `histogram_quantile()` استفاده میشود:
promql
histogram_quantile(0.99, rate(http_request_duration_seconds_bucket[10m]))این کوئری صدک ۹۹ام latency را بر اساس histogram bucketها محاسبه میکند. در محیطهای enterprise، percentileها برای شناسایی tail latency، backlog، saturation، و رفتار کاربران در بار بالا ضروری هستند.
ه) تشخیص روند و پیشبینی
Prometheus حتی میتواند برای پیشبینی روندهای آینده استفاده شود. تابع `predict_linear()` برای برآورد خطی آینده کاربرد دارد.
مثال:
promql
predict_linear(node_filesystem_free_bytes[4h], 24 3600) < 0این کوئری بررسی میکند که آیا فضای دیسک طی ۲۴ ساعت آینده بر اساس روند ۴ ساعت گذشته به زیر صفر میرسد یا نه. چنین تحلیلی برای جلوگیری از outages ناشی از full disk بسیار ارزشمند است.
و) مقایسه بازههای زمانی
PromQL امکان مقایسه متریکها در زمانهای مختلف را فراهم میکند. مثلاً میتوان وضعیت امروز را با دیروز یا هفته گذشته مقایسه کرد. این موضوع برای شناسایی تغییرات پس از deploy، seasonality، یا چرخههای بار بسیار مهم است.
ز) تجمیع و grouping
در محیطهای distributed، یک متریک بهتنهایی کافی نیست. باید دادهها را با `sum by(...)`، `avg by(...)`، `max by(...)` و سایر عملگرها تجمیع کرد تا تصویر درستتری از رفتار سیستم بهدست آید.
مثلاً میتوان latency را بر اساس سرویس، namespace، cluster، یا region تجزیه کرد و فهمید مشکل دقیقاً از کجا شروع شده است.
ح) PromQL در فضای تولید
PromQL تنها برای نمایش نمودار نیست؛ برای alerting، SLO management، capacity planning، anomaly detection، و RCA هم استفاده میشود. همین ویژگی باعث شده یکی از مهمترین مهارتها برای SRE، DevOps و platform engineers باشد.
داشبورد Grafana با کوئری_های PromQL برای تحلیل زمان_بندی و متریک_های سیستم👇
۴. گرافانا (Grafana): از داشبوردهای خستهکننده تا اتاق جنگ (War Room)
اگر Prometheus موتور جمعآوری و تحلیل است، Grafana لایهی دیدن، فهمیدن و تصمیم گرفتن است. Grafana فقط یک ابزار رسم نمودار نیست؛ یک پلتفرم observability visualization است که میتواند دادهها را از منابع مختلف بگیرد و در قالبی تعاملی، قابلفهم و سازمانی ارائه کند.
الف) داشبورد بهعنوان محصول
در سازمانهای حرفهای، داشبورد فقط یک صفحه نمودار نیست. داشبورد یک محصول داخلی است که برای نقشهای مختلف طراحی میشود:
dashboard برای SRE
dashboard برای توسعهدهنده
dashboard برای مدیر محصول
dashboard برای مدیریت ارشد
dashboard برای عملیات شبانهروزی
هر گروه به سطح متفاوتی از اطلاعات نیاز دارد. Grafana این امکان را میدهد که همین لایهبندی را بهخوبی پیادهسازی کنید.
ب) Templating و Variables: داشبوردهای پویا
بهجای ساختن دهها یا صدها داشبورد تکراری، میتوان از variables استفاده کرد. برای مثال:
`$cluster`
`$namespace`
`$pod`
`$service`
`$instance`
`$env`
با این روش، یک داشبورد واحد میتواند برای هزاران target مختلف استفاده شود. این قابلیت در محیطهای چندکلاستری و چندمحیطی مثل dev/stage/prod بسیار مهم است.
ج) Data Source Blending: تلفیق داده از چند منبع
Grafana محدود به Prometheus نیست. شما میتوانید در یک داشبورد، دادههای زیر را کنار هم ببینید:
metrics از Prometheus
logs از Loki یا Elasticsearch
traces از Tempo یا Jaeger
دادههای تحلیلی از PostgreSQL یا MySQL
اطلاعات business از APIهای داخلی
این ادغام باعث میشود تحلیل از «فقط دیدن یک نمودار» به «فهمیدن کامل رخداد» تبدیل شود. مثلاً ممکن است latency بالا رفته باشد، لاگها نشان دهند errorهای timeout در افزایشاند، و traceها هم dependency خاصی را بهعنوان bottleneck معرفی کنند.
د) Annotations: وصل کردن رخدادهای عملیاتی به نمودارها
یکی از قابلیتهای بسیار ارزشمند Grafana، Annotations است. این ویژگی به شما اجازه میدهد رخدادهای مهم را روی نمودار ثبت کنید:
deploy نسخه جدید
restart سرویس
failover دیتابیس
rotate شدن certificate
افزایش ناگهانی traffic
شروع campaign بازاریابی
اعمال تغییر در feature flag
وقتی روی نمودار یک spike میبینید، annotationها کمک میکنند بفهمید آن spike با چه رویدادی همزمان بوده است. این قابلیت در تحلیل incident و postmortem بسیار مهم است.
ه) آژانگستن سازی داشبورد: از نمایش به تجربه
Grafana فقط برای نمایش نیست؛ برای تجربه کاربر عملیاتی نیز طراحی شده است. شما میتوانید:
thresholds تعریف کنید
رنگهای وضعیت را مشخص کنید
drilldown بسازید
لینک به دیگر داشبوردها اضافه کنید
rowها و panelها را شرطی کنید
repeat panel بر اساس variable داشته باشید
در نتیجه، داشبورد دیگر یک صفحهی ثابت نیست؛ بلکه یک محیط زنده و عملیاتی است.
و) War Room و Decision Support
در incidentهای جدی، Grafana به اتاق جنگ تبدیل میشود. تیم عملیات، توسعه و زیرساخت همه یک داشبورد مشترک را نگاه میکنند. یک نگاه دقیق به panelها میتواند مشخص کند:
آیا مشکل از CPU saturation است؟
آیا memory leak رخ داده؟
آیا network latency بالا رفته؟
آیا تعداد درخواستهای ۵xx بیشتر شده؟
آیا یک rollout جدید در حال خراب کردن سیستم است؟
در چنین لحظاتی، Grafana نقش یک ابزار تصمیمسازی بلادرنگ را بازی میکند.
داشبورد Grafana با تم تیره و نمودارهای Gauge برای CPU و Load👇
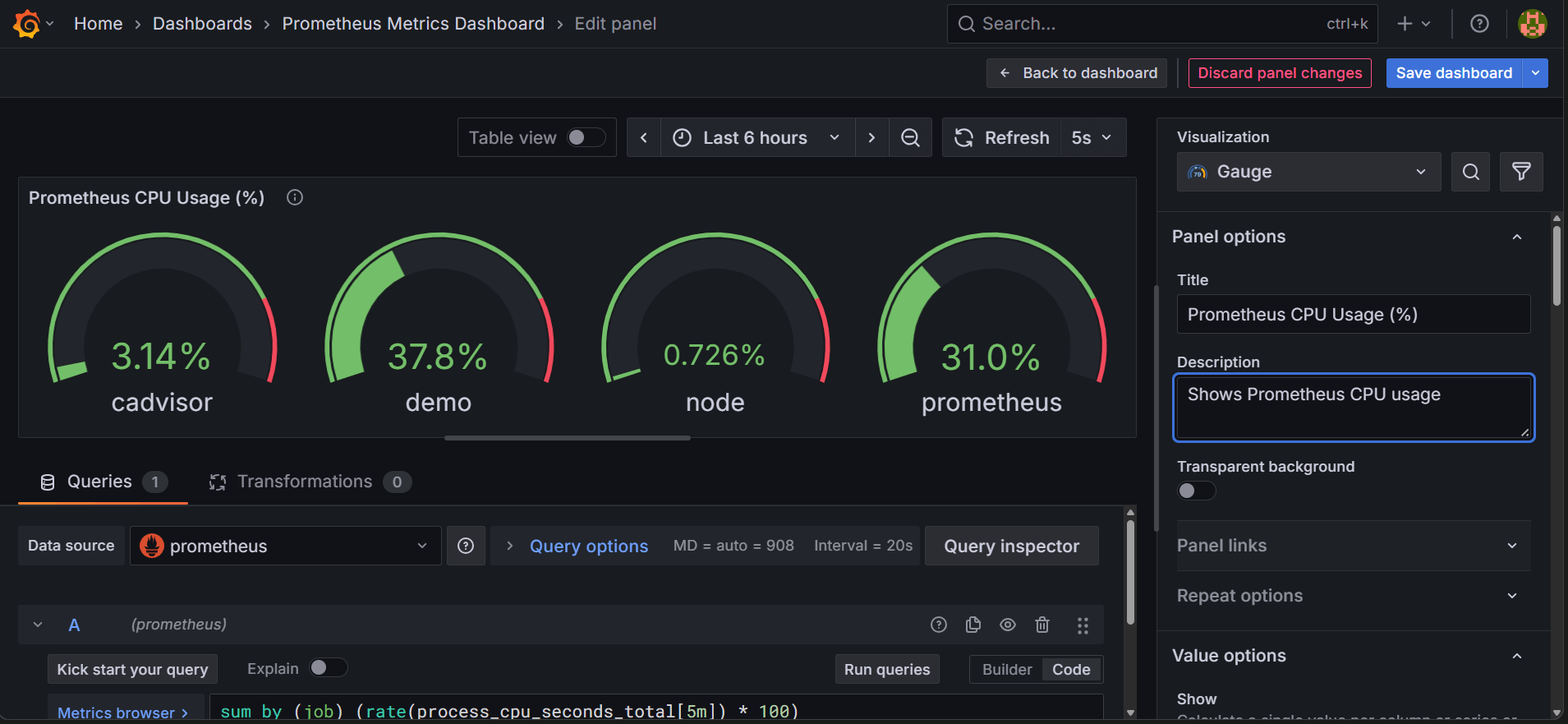
۵. مقیاسپذیری بینهایت: غلبه بر محدودیتهای پرومتئوس با Thanos
Prometheus در طراحی اولیه خود، بهصورت singlenode TSDB ساخته شده است. این یعنی بسیار سریع، ساده، و قابلاعتماد است؛ اما در عین حال برای نگهداری بلندمدت و مقیاس جهانی، به تنهایی کافی نیست.
اگر شما فقط یک Prometheus داشته باشید، چند مسئله مطرح میشود:
در صورت خرابی سرور، data loss محتمل است
retention محلی محدود است
queryهای crosscluster دشوار میشوند
aggregation جهانی در چند region سخت میشود
longterm storage به صورت native در خود Prometheus ایدهآل نیست
برای حل این محدودیتها، لایههایی مانند Thanos، Cortex و در برخی سناریوها Grafana Mimir وارد میشوند.
الف) Thanos چیست؟
Thanos یک لایه تکمیلی برای Prometheus است که قابلیتهای زیر را فراهم میکند:
HA برای Prometheus
longterm storage
query federation جهانی
deduplication
downsampling
global aggregation
اتصال به object storage
Thanos معمولاً با معماری sidecar کنار هر Prometheus اجرا میشود و دادهها را به object storage مانند Amazon S3 یا فضای ذخیرهسازی سازگار با S3 منتقل میکند.
ب) اجزای مهم Thanos
Sidecar
کنار Prometheus اجرا میشود و بلوکها را به object storage upload میکند. همچنین queryها را برای دسترسی به دادههای محلی و بلندمدت پشتیبانی میکند.
Query
لایهای برای query سراسری است که میتواند چندین Prometheus را بهصورت یکپارچه query کند.
Store Gateway
بلوکهای قدیمیتر را از object storage سرویس میکند.
Compactor
وظیفه فشردهسازی، downsampling و نگهداری ساختاری دادههای تاریخی را بر عهده دارد.
Ruler
برای evaluation ruleها و alerting در معماری توزیعشده استفاده میشود.
ج) چرا Thanos در enterprise مهم است؟
در سازمانهای بزرگ، شما ممکن است چندین cluster در چند region، چند cloud provider، یا چند دیتاسنتر داشته باشید. بدون یک layer مانند Thanos، تحلیل crossenvironment بسیار سخت میشود. Thanos یک global view فراهم میکند، یعنی از دید تیم عملیات، کل زیرساخت بهصورت یک سیستم واحد دیده میشود.
این موضوع نهفقط برای مانیتورینگ، بلکه برای compliance، capacity planning، incident review و SLA governance نیز اهمیت دارد.
د) ذخیرهسازی نامحدود و ارزانتر
Object storage نسبت به local SSD برای نگهداری طولانیمدت ارزانتر و مناسبتر است. به این ترتیب، Prometheus میتواند در لایه local فقط دادههای نزدیک و فوری را نگه دارد، در حالی که Thanos آرشیو بلندمدت را بر عهده میگیرد.
معماری Thanos شامل Sidecar، Query، Store Gateway، Compactor و اتصال به Object Storage👇
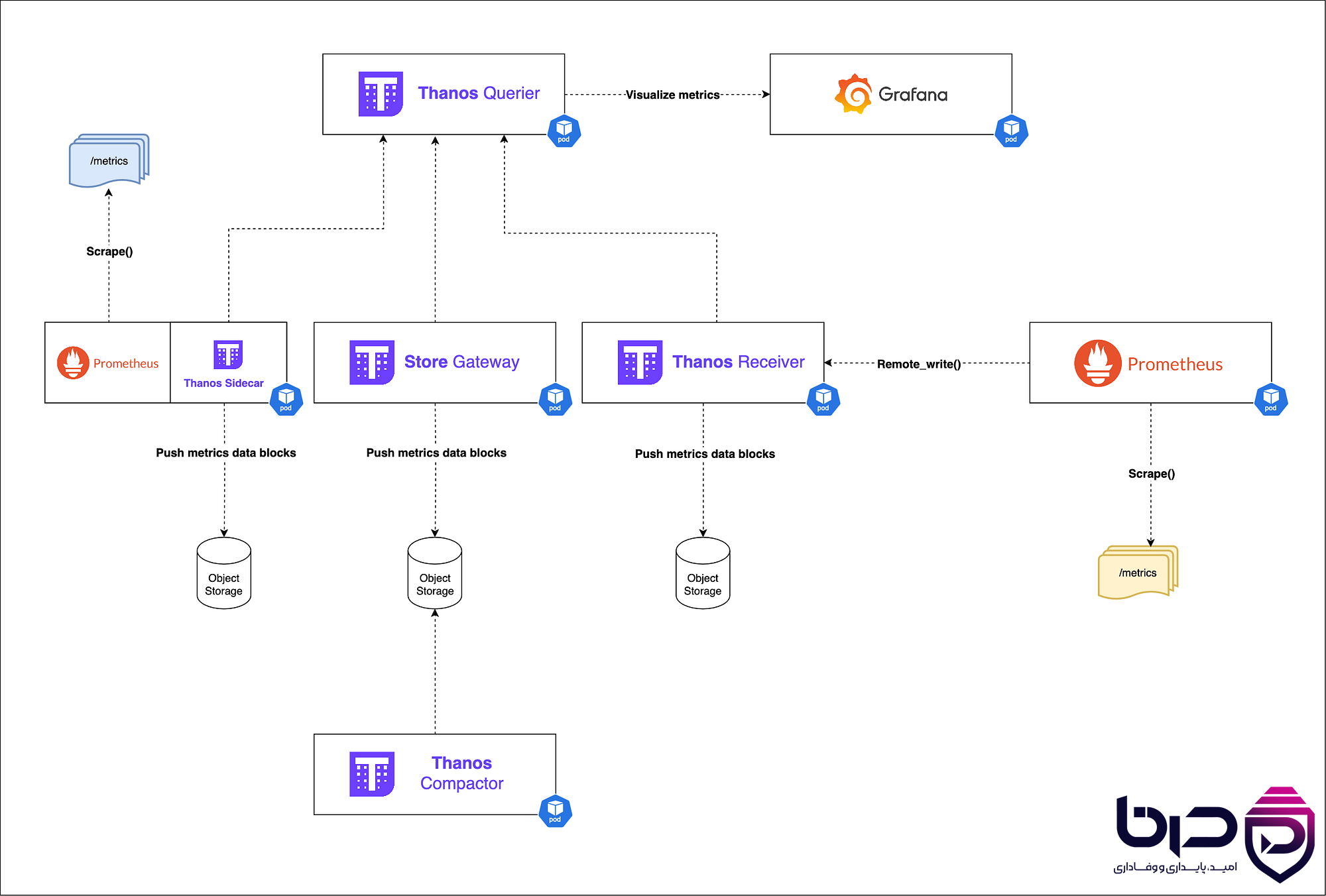
۶. سیستم هشدار عصبی: Alertmanager در خط مقدم
Observability بدون alerting کامل نیست. اگر سیستم شما متوجه خطا شود اما هیچ هشدار مناسبی ارسال نکند، عملاً در لحظه بحران بیفایده خواهد بود. در اکوسیستم Prometheus، این نقش را Alertmanager ایفا میکند.
Alertmanager فقط یک notifier ساده نیست؛ بلکه یک موتور مدیریت آلارم است که برای جلوگیری از انفجار هشدار، مسیریابی هوشمند، و کنترل نویز طراحی شده است.
الف) Grouping: جلوگیری از سیل هشدار
وقتی یک dependency اصلی مثل database down شود، ممکن است دهها یا صدها سرویس downstream هم شروع به خطا دادن کنند. اگر هر سرویس جداگانه alert بفرستد، تیم عملیات در چند ثانیه زیر حجم پیام دفن میشود.
Alertmanager با grouping هشدارهای مرتبط را در یک دسته جمع میکند تا فقط یک alert معنادار به تیم برسد. این کار باعث کاهش چشمگیر alert fatigue میشود.
ب) Inhibition: اولویت دادن به علت اصلی
گاهی یک alert علت اصلی است و بقیه فقط نشانههای ثانویه آن هستند. مثلاً اگر node فیزیکی down شده باشد، alertهای مربوط به podها یا کانتینرهای داخل آن node عملاً تکراریاند. Alertmanager میتواند آنها را inhibit کند تا فقط alert اصلی نمایش داده شود.
ج) Routing: رساندن هشدار به تیم مناسب
تمام alertها یکسان نیستند. برخی باید به تیم توسعه برسند، برخی به تیم زیرساخت، برخی به oncall، و برخی باید فوری به مدیر شیفت یا کانال incident منتقل شوند. Alertmanager با route tree این تفکیک را انجام میدهد.
بهطور مثال:
Warning → Slack یا Teams
Critical → PagerDuty یا تماس تلفنی
Infrastructure issue → تیم platform
Application bug → تیم development
Security anomaly → تیم SOC
د) Silencing و Maintenance Window
در محیط عملیاتی، گاهی لازم است هشدارها موقتاً خاموش شوند؛ مثلاً هنگام maintenance، migration، deploy، یا تست بار. Alertmanager این امکان را فراهم میکند که alertها را silence کنید تا نویز غیرضروری ایجاد نشود.
ه) Alert Design اصولی
هشدار خوب باید:
روی symptom یا SLO حساس باشد، نه فقط روی علتهای سطح پایین
دقیق و قابلاقدام باشد
نویز کم داشته باشد
ownership مشخص داشته باشد
severity واقعی داشته باشد
تاریخچه و context کافی ارائه دهد
یک alert بد، تیم را خسته میکند. یک alert خوب، زمان واکنش را نجات میدهد.
معماری Alertmanager Grouping، Deduplication، Silencing و Routing به کانالهای اطلاعرسانی👇
۷. الگوهای استقرار حرفهای در Kubernetes و CloudNative
استفاده از Prometheus و Grafana در محیطهای production صرفاً نصب ساده یک سرویس نیست. برای اینکه این استک بهخوبی کار کند، باید طراحی معماری آن نیز درست باشد.
الف) Single Prometheus برای شروع، ولی نه برای همیشه
برای محیطهای کوچک و متوسط، یک Prometheus میتواند کافی باشد. اما بهمحض افزایش تعداد targetها، cardinality، و نیازهای retention، باید به سمت معماریهای توزیعشده رفت.
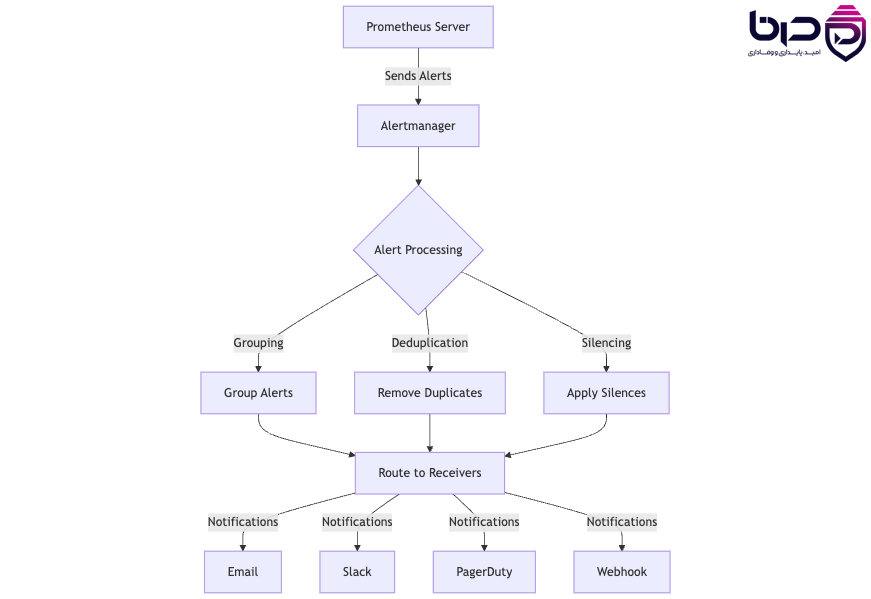
ب) Prometheus Operator
در Kubernetes، یکی از بهترین روشها برای مدیریت Prometheus استفاده از Prometheus Operator است. این operator باعث میشود اشیای Kubernetesnative مانند:
ServiceMonitor
PodMonitor
PrometheusRule
Alertmanager
ThanosRuler
بهصورت declarative مدیریت شوند.
این الگو هم عملیات را سادهتر میکند و هم با GitOps و Infrastructure as Code سازگارتر است.
ج) Namespacebased Monitoring
در کلاسترهای بزرگ، معمولاً متریکها بر اساس namespace، team، environment و tenant سازماندهی میشوند. این کار باعث میشود هر تیم دید مستقل اما استانداردی به سرویسهای خود داشته باشد.
د) Scrape Strategy و Load Control
در مقیاس بالا باید حتماً به موارد زیر توجه کرد:
scrape interval
scrape timeout
number of targets
series cardinality
relabeling rules
metric drop strategy
remote write load
resource requests/limits
Prometheus برای performance مناسب، به CPU، RAM، و especially I/O مناسب نیاز دارد. TSDB یک workload نوشتن مداوم و خواندن تحلیلی دارد و همین موضوع آن را به سیستمی حساس به storage performance تبدیل میکند.
ه) High Availability
برای HA، معمولاً چند instance از Prometheus در کنار هم اجرا میشوند. دادهها بهصورت duplicate scrape میشوند و سیستمهای بالادستی مانند Thanos deduplication را انجام میدهند. این الگو باعث میشود خرابی یک instance به معنای از دست رفتن observability نباشد.
معماری Prometheus Operator با ServiceMonitor و PodMonitor در Kubernetes👇
۸. از متریک تا تصمیم تجاری: چرا این استک فقط ابزار فنی نیست؟
یکی از اشتباهات رایج این است که Prometheus و Grafana را فقط ابزار DevOps بدانیم. در واقع، این استک اگر درست استفاده شود، بهطور مستقیم بر تصمیمهای کسبوکار اثر میگذارد.
الف) اتصال observability به SLO و SLA
با Prometheus میتوان دقیقاً سنجید:
چند درصد درخواستها موفق بودهاند
latency واقعی کاربران چقدر است
نرخ خطا در چه بازهای از بودجه خطا عبور کرده
کدام سرویس بیشترین ریسک را برای SLA ایجاد میکند
ب) ظرفیتسنجی و Planning
اگر متریکهای CPU، RAM، disk, network, queue depth, connection pool و request rate را بهصورت تاریخی داشته باشید، میتوانید:
growth trend را تشخیص دهید
زمان لازم برای scale را پیشبینی کنید
هزینه زیرساخت را تخمین بزنید
bottleneckهای آینده را قبل از رخ دادن شناسایی کنید
ج) تحلیل اثر Releaseها
با annotation و مقایسه نسخهها، میتوان فهمید یک release جدید چه اثری روی latency، error rate یا resource consumption داشته است. این یعنی observability مستقیماً به کیفیت delivery و reliability مربوط است.
د) پشتیبانی از فرهنگ Postmortem
بعد از هر incident، متریکها و داشبوردها بهترین منبع برای بازسازی حقیقت هستند. از روی آنها میتوان فهمید:
چه زمانی مشکل شروع شد
کدام dependency نخستین سیگنال را داد
چه تغییری باعث تشدید بحران شد
در چه لحظهای تیم باید مداخله میکرد
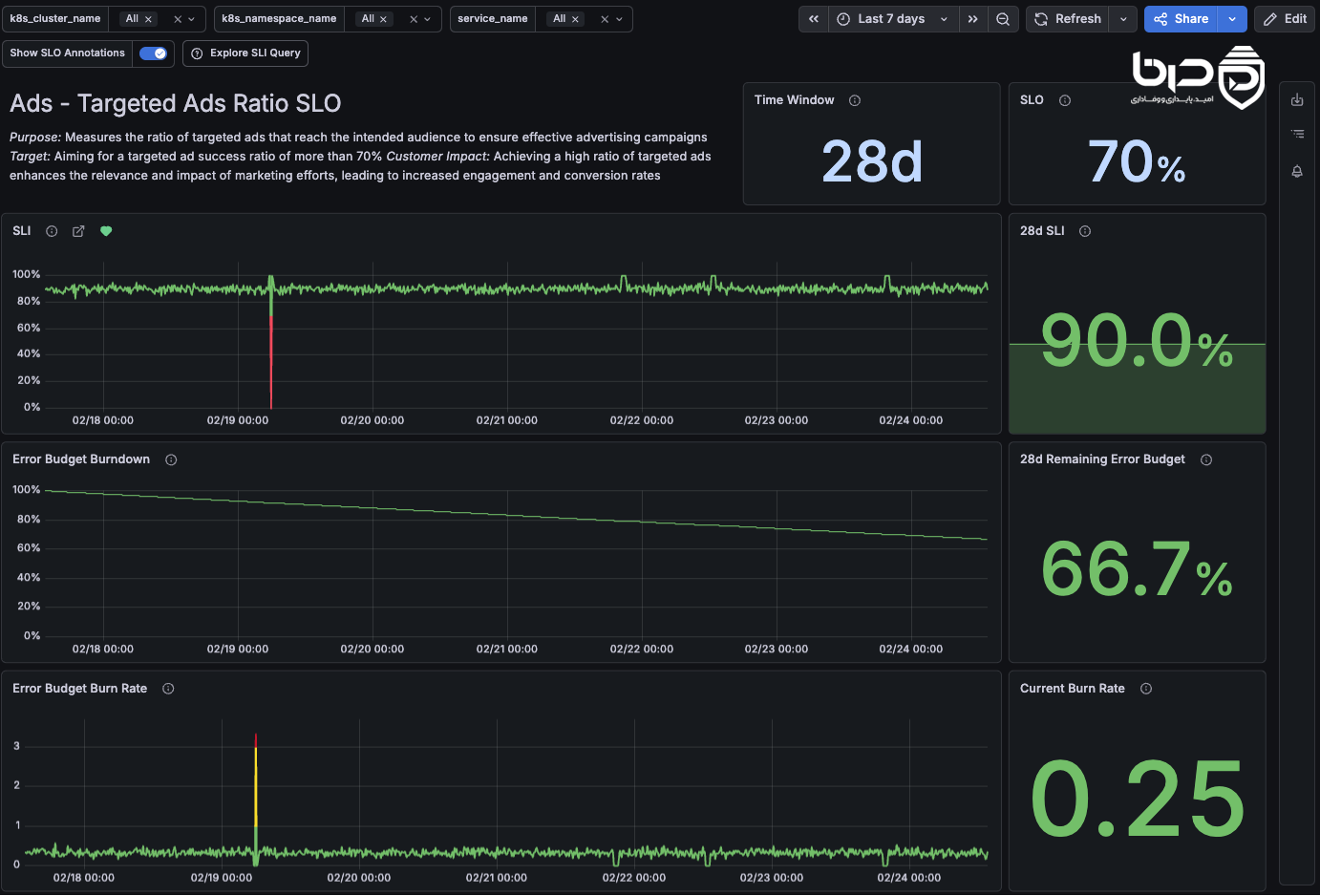
داشبورد SLO در Grafana نمایش Error Budget Burn Rate و وضعیت SLA👇
نتیجهگیری & Call To Action
- در سال ۲۰۲۶، استک Prometheus و Grafana دیگر یک گزینه تزئینی یا صرفاً فنی نیست؛ این دو ابزار به بخشی از زیرساخت حیاتی سازمان تبدیل شدهاند. در معماریهای مدرن، failure نه یک رویداد استثنایی، بلکه بخشی از واقعیت سیستمهای پیچیده است. تفاوت سازمانهای موفق و ناموفق در این است که آیا میتوانند failure را سریع ببینند، تحلیل کنند، و از آن یاد بگیرند یا نه.
- Prometheus به شما قدرت میدهد که سیستم را با زبان متریکهای دقیق، پایدار و سریزمانی ببینید. Grafana این دادهها را به دانش عملیاتی تبدیل میکند. Thanos آن را به مقیاس enterprise میرساند. Alertmanager آن را به action تبدیل میکند. و در کنار هم، این stack یک برج مراقبت تمامعیار برای دنیای cloudnative میسازد.
- زیرساخت ابری ایدهآل برای چنین معماریای باید از storage سریع، I/O پایدار، منابع RAM کافی، و شبکه کمتاخیر برخوردار باشد. اگر متریکها قلب observability باشند، storage و compute مناسب رگهای حیاتی آن هستند. یک Prometheus کند یا یک Grafana ناپایدار، میتواند خود به منبع مشکل تبدیل شود.
- در نهایت، observability فقط دیدن نمودار نیست؛ فهمیدن رفتار سیستم پیش از تبدیل شدن آن به بحران است. و همین تفاوت است که Prometheus و Grafana را از ابزارهای ساده monitoring به ستونهای اصلی reliability engineering تبدیل میکند.
اگر میخواهید یک قدم جلوتر از رقبا باشید، باید امروز اقدام کنید.😁
زیرساخت خود را بهینه کنید، مانیتورینگ خود را حرفه ای و به روز کنید ، Prometheus و Grafana ابزاریست که انتظار مانیتورینگ شمارا میکشد.