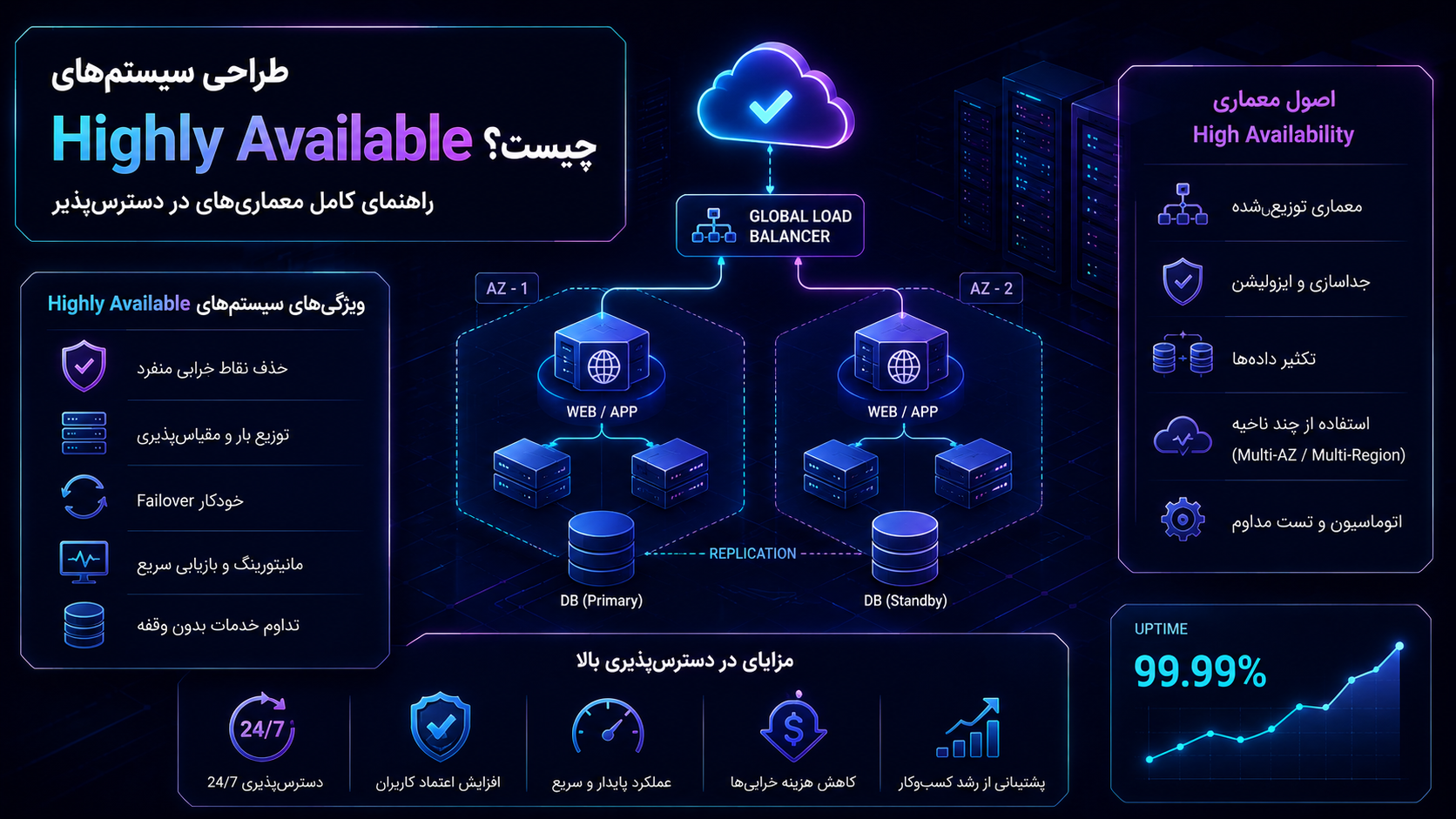
در معماریهای مدرن، «بالا بودن سرویس» دیگر به معنای واقعی کلمهی قدیمیاش محدود نمیشود. امروز یک سرویس ممکن است روی چند Availability Zone، چند Region، چند دیتابیس، چند load balancer، چند لایهی شبکه و مجموعهای از microserviceها اجرا شود و همچنان باید در برابر خرابیهای روزمره، جهش ترافیک، failoverهای برنامهریزینشده و اختلالات زیرساختی مقاوم بماند. Azure بهصراحت میگوید high availability یعنی طراحی راهحل بهگونهای که در برابر مشکلات روزمره resilient باشد و نیازهای کسبوکار برای availability را برآورده کند، و AWS نیز availability را درصد زمانی تعریف میکند که workload هنگام نیاز واقعاً قابل استفاده باشد.
High availability یا HA فقط یک ویژگی فنی نیست؛ یک استراتژی معماری است. در عمل، HA یعنی از همان روز اول طراحی، فرض کنیم failure رخ میدهد، اما این failure نباید به outage تبدیل شود. Google Cloud در راهنمای خود میگوید برای HA باید سرویسها و applicationها را در چند zone و region توزیع و replicate کرد و automatic failover را برای ادامهی سرویس در زمان outage فعال نمود. این نگاه، HA را از «امید به پایداری» به «مهندسی پایداری» تبدیل میکند.
۱. Highly Available یعنی چه و چه چیزی نیست؟
سیستم highly available سیستمی است که در برابر خرابی یک جزء، یک host، یک node، یک zone یا حتی یک region کامل، همچنان به کار ادامه میدهد یا خیلی سریع بازیابی میشود. AWS در Reliability Pillar availability را درصد زمانی میداند که workload در زمان نیاز، وظیفهی توافقشدهی خود را با موفقیت انجام میدهد. SRE Google هم توضیح میدهد که availability معمولاً در قالب «nines» بیان میشود و 100% availability عملاً دستنیافتنی است.
اما HA با Disaster Recovery یکی نیست. Azure بهصورت رسمی HA را برای اختلالات روزمره و DR را برای رویدادهای بزرگتر و disaster-level تعریف میکند. یعنی HA برای day-to-day issues است و DR برای وقتی که یک منطقه، سایت یا بخش مهمی از زیرساخت واقعاً از دسترس خارج شده باشد. این تمایز حیاتی است، چون بسیاری از سیستمها HA خوبی دارند اما DR ضعیفی دارند، یا برعکس.
مثال
یک سرویس وب که روی دو VM در دو availability zone اجرا شده و پشت load balancer قرار دارد، ممکن است HA خوبی داشته باشد. اما اگر هر دو zone در یک region باشند و آن region دچار outage گسترده شود، این سیستم هنوز DR کامل ندارد. همین تفاوت، مرز میان HA و DR را مشخص میکند.
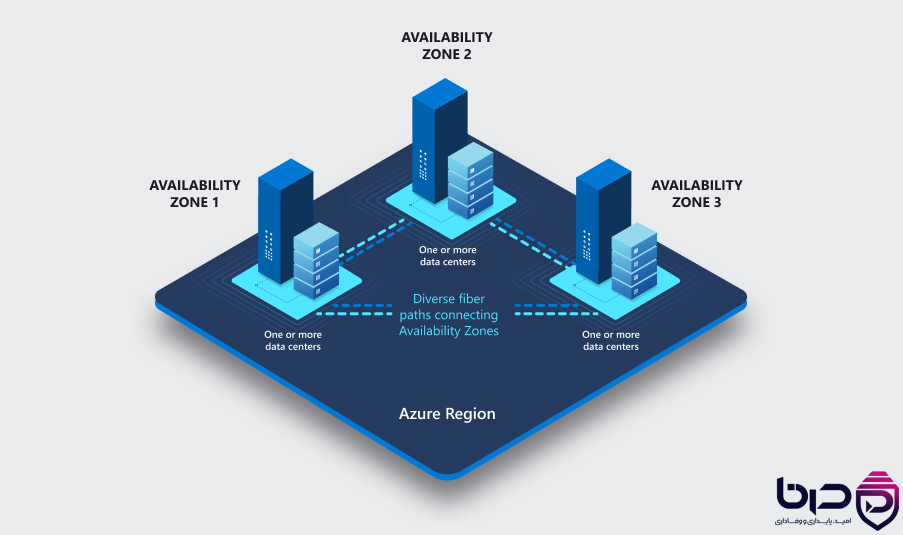
Azure Availability Zones - ۳ Zone با دیتاسنترهای مستقل در یک Region👇
۲. معماری Highly Available از چه ایدهای شروع میشود؟
ایدهی مرکزی HA این است: single point of failure را حذف کن. AWS در راهنمای Reliability و همچنین در راهنمای high availability and scalability خود تأکید میکند که باید no single point of failure طراحی شود و از الگوهایی مثل scalable load-balanced cluster یا active-standby pair استفاده شود. Google Cloud هم در building blocks of reliability روی redundancy، replication و separation of failure domains تأکید میکند.
یعنی اگر یک component خراب شد، سیستم نباید متوقف شود. این component میتواند network path، load balancer، app server، database leader، storage node یا حتی DNS entry باشد. در HA واقعی، هر لایه باید طوری طراحی شود که خرابی جزء منفرد، خرابی کل سیستم نشود. این همان فلسفهای است که طراحی reliable systems را از طراحی «فقط کار میکند» جدا میکند.
مثال
اگر یک فروشگاه آنلاین فقط یک web server داشته باشد، با خرابی همان یک سرور سایت میخوابد. اما اگر سه یا بیشتر instance در چند zone، پشت load balancer و با health check فعال داشته باشد، خرابی یک instance به outage تبدیل نمیشود. AWS ELB و Google Cloud Load Balancing دقیقاً برای همین سناریو ساخته شدهاند: توزیع traffic روی backendهای متعدد و حذف وابستگی به یک نقطهی منفرد.
۳. Failure Domain یعنی چه و چرا در HA مهم است؟
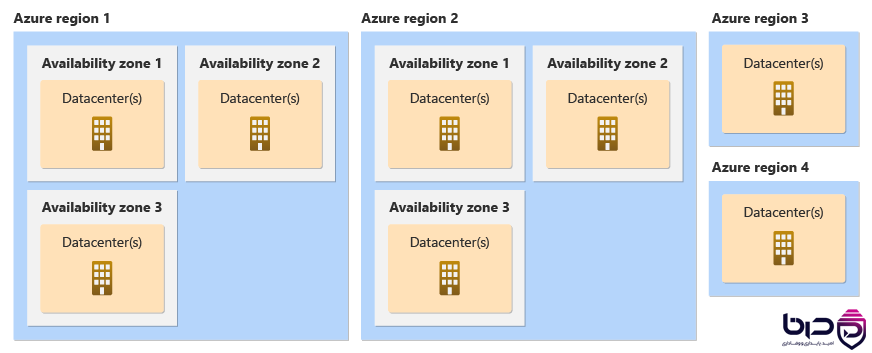
Failure domain به محدودهای گفته میشود که اگر در آن خرابی رخ دهد، مجموعهای از منابع تحت تأثیر قرار میگیرند. Google Cloud بهصورت رسمی از zones، regions و location-scoped resources بهعنوان building blocks reliability یاد میکند و AWS و Azure نیز availability zoneها را بهعنوان واحدهای مستقل برای تحمل خرابی معرفی میکنند. Azure میگوید هر zone برق، سرمایش و شبکهی مستقل دارد تا اگر یک zone دچار outage شد، zoneهای دیگر همچنان service را نگه دارند.
در طراحی HA باید اول failure domainها را map کنی: instance، rack، host، zone، region، network path، storage cell و dependencyهای بیرونی. اگر این نقشه را نداشته باشی، ممکن است فکر کنی redundancy داری، در حالی که همهی replicaها در یک failure domain مشترک هستند. Google Cloud explicitly میگوید باید failure domains را از VM تکی تا region بشناسی و بر اساس آن redundancy طراحی کنی.
مثال
دو VM در یک host فیزیکی متفاوت هستند، اما اگر هر دو داخل یک zone باشند، هنوز در برابر outage zone آسیبپذیرند. دو DB replica هم اگر روی یک storage backend مشترک قرار داشته باشند، هنوز یک failure domain مشترک دارند. HA واقعی یعنی redundancy در failure domainهای متفاوت.
Azure Region و Availability Zones - Region ۱ تا ۴ با Datacenterها👇
۴. Redundancy فقط «دو تا بودن» نیست
Redundancy در HA یعنی یک resource بحرانی را فقط یکبار نداشته باشی. اما redundancy هوشمند باید در مسیر درست باشد: compute، network، storage، DNS، identity، messaging و observability. AWS میگوید achievable high availability معمولاً با load-balanced cluster یا active-standby pair ساخته میشود و Google Cloud نیز replication across zones and regions را پایهی HA معرفی میکند.
این یعنی اگر فقط serverها را دوبرابر کنی ولی دیتابیس single باشد، هنوز HA واقعی نداری. اگر فقط دیتابیس multi-AZ باشد ولی DNS یا load balancer single point of failure باشند، باز هم سیستم شکننده است. HA یک property سیستمی است، نه یک feature isolated.
مثال
یک API ممکن است روی دو app server اجرا شود، اما اگر sessionها روی local memory ذخیره شوند و هیچ shared state یا sticky-session strategy درستی نباشد، با failover بخشی از کاربران session خود را از دست میدهند. در اینجا compute redundant است، ولی application state هنوز single point of failure دارد.
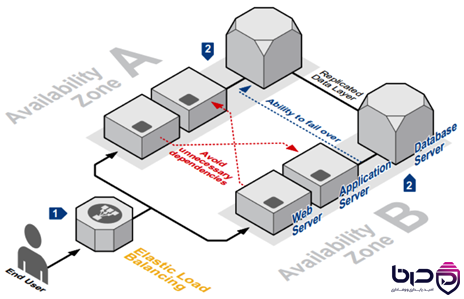
AWS HA Architecture - Elastic Load Balancing در AZ A و B با Database Server👇
۵. Load Balancer چرا ستون فقرات HA است؟
Load balancer یکی از مهمترین اجزای هر سیستم highly available است، چون traffic را بین چند target پخش میکند و فقط به backendهای healthy درخواست میفرستد. AWS میگوید ELB ترافیک را به multiple targets در یک یا چند Availability Zone توزیع میکند، سلامت targetها را monitor میکند و وقتی target unhealthy شود، ترافیک را به آن نمیفرستد. Azure هم میگوید Load Balancer خدمات highly available ایجاد میکند و حتی میتواند millions of flows را پشتیبانی کند. Google Cloud نیز load balancing managed و highly available را بهعنوان ستون resilience و performance معرفی میکند.
Load balancer فقط برای scale نیست؛ برای resilience هم هست. وقتی traffic روی چند backend پخش میشود، خرابی یک node لزوماً به outage تبدیل نمیشود. اگر health checkها درست تنظیم شده باشند، load balancer میتواند unhealthy instance را از pool خارج کند و recovery را بدون دخالت دستی ادامه دهد. AWS و Google Cloud هر دو صریحاً health check و routing only to healthy targets را جزو پایههای HA میدانند.
مثال
در Google Cloud، load balancing میتواند traffic را به backendهایی در چند region بفرستد و برای high availability even during zonal outage استفاده شود. در AWS نیز ALB traffic را میان targets در چند AZ توزیع میکند. این تفاوت سادهی معماری، در عمل تفاوت میان یک outage کوچک و یک outage بزرگ است.
Deep Health Check - Healthy HTTP 200، Unhealthy HTTP 500👇
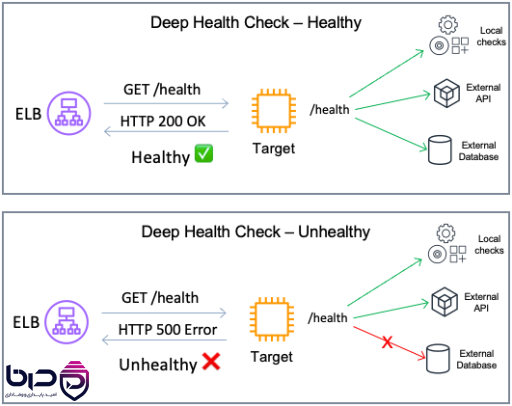
۶. Stateless بودن چرا در HA اینقدر مهم است؟
سرویسهای stateless برای HA بسیار مناسبترند، چون state session را در خود نگه نمیدارند و به همین دلیل میتوانند بهراحتی scale شوند یا failover بگیرند. اگر application state به memory محلی گره بخورد، تعویض instance یا node میتواند session loss ایجاد کند. Load balancerها و managed serviceهای cloud عملاً برای چنین معماریهایی ساخته شدهاند.
البته stateless بودن همیشه به معنای حذف state نیست؛ بلکه به معنای externalizing state است. یعنی session، cache، transaction state یا queue state باید در لایهای بیرونی و مقاوم نگهداری شود. اینجا است که design thinking اهمیت پیدا میکند: application لایهی اجراست، اما state باید در لایهی مناسب خود مدیریت شود.
مثال
یک وباپلیکیشن auth اگر tokenها را به شکل قابلاعتبارسنجی و بیرونی ذخیره کند، با خراب شدن یک app server کاربرانش را از دست نمیدهد. اما اگر session فقط در RAM همان server نگهداری شود، failover برابر است با logout گسترده. این مسئله در HA از جزئیات کوچکِ صرفاً فنی به یک عامل مستقیم تجربهی کاربری تبدیل میشود.
Stateful vs Stateless - Stateful State Storage، Stateless Request Contains All Info👇
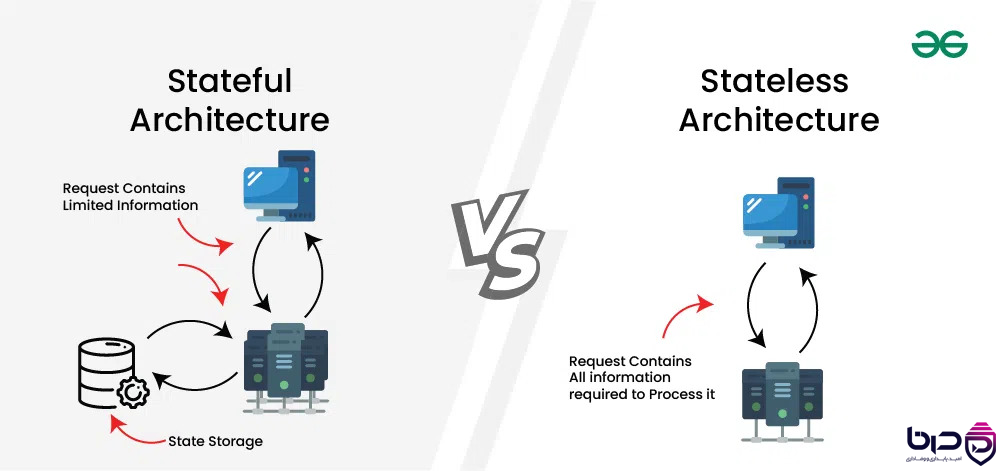
۷. Active-Active و Active-Passive چه تفاوتی دارند؟
در active-active، چند site یا چند cluster همزمان traffic را سرویس میدهند. در active-passive، یک site اصلی فعال است و سایت دیگر standby میماند تا اگر اصلی از کار افتاد، traffic به secondary منتقل شود. AWS Route 53 این دو الگو را بهصورت رسمی توضیح میدهد و میگوید active-passive برای حالتی مناسب است که primary باید اکثر زمانها فعال باشد و secondary در standby بماند. Azure AKS نیز یک solution active-active را بهعنوان recommended HA pattern در دو paired region با دو cluster فعال معرفی میکند.
Active-active معمولاً resilience و utilization بهتری میدهد، اما complexity آن بالاتر است؛ باید data consistency، traffic steering و conflict handling را جدی گرفت. Active-passive سادهتر است، ولی failover ممکن است کندتر و capacity نهایی کماستفادهتر باشد. Azure برای بعضی NVAها هم active/passive را معرفی میکند و حتی به convergence time یک تا دو دقیقه اشاره میکند، که نشان میدهد مدل passive هنوز در بسیاری از سناریوها کاربرد دارد.
مثال
اگر یک سرویس مالی real-time داری، active-active در چند region میتواند تجربهی بهتری بدهد، اما اگر consistency بسیار حساس باشد و تیم operational کوچکی داشته باشی، active-passive گاهی منطقیتر است. انتخاب pattern باید با trade-offهای business، consistency و operational maturity هماهنگ باشد.
Active-Active هر دو Node Active، Active-Passive Node ۲ Passive با Failover👇
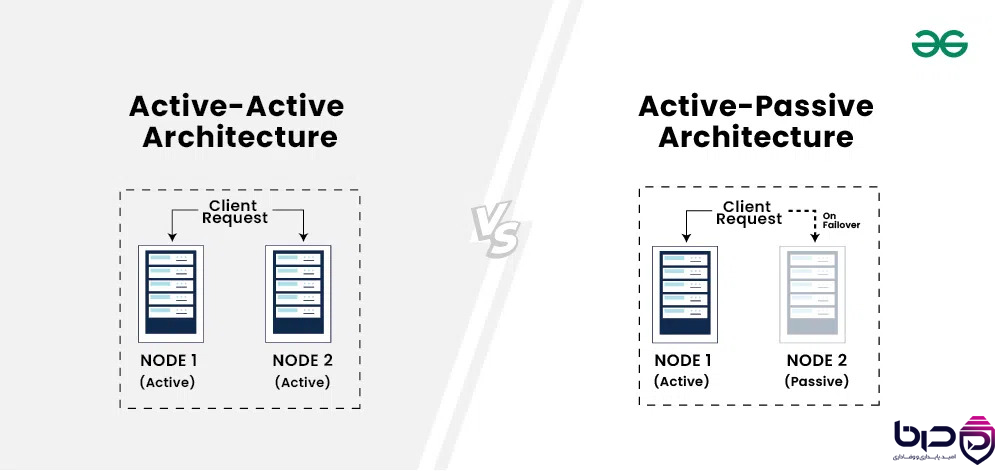
۸. Database در سیستمهای HA چه جایگاهی دارد؟
پایگاه داده معمولاً سختترین بخش HA است، چون هم stateful است و هم consistency-sensitive. به همین دلیل managed database services معمولاً الگوهای HA جداگانه دارند. Amazon RDS Multi-AZ availability، durability و fault tolerance را افزایش میدهد و در رخداد maintenance یا disruption بهصورت خودکار failover انجام میدهد. Aurora نیز داده را بهصورت همزمان در چند AZ و روی storage nodes متعدد replicate میکند و failover را برای resilience بالاتر پشتیبانی میکند.
Azure Database for MySQL Flexible Server نیز HA با automatic failover ارائه میدهد و صریحاً میگوید این کار کمک میکند committed data از بین نرود و database به single point of failure تبدیل نشود. در Google Cloud نیز Cloud SQL HA و AlloyDB HA برای نگهداشتن availability و failover در چند zone طراحی شدهاند.
مثال
اگر application شما multi-AZ باشد ولی database single-node، در واقع HA لایهی compute را دارید ولی HA لایهی داده را نه. یک DB failover نشده میتواند کل سیستم را متوقف کند، حتی اگر app serverها همه سالم باشند. برای همین HA واقعی همیشه باید از data layer شروع شود، نه فقط از web tier.
SQL Server Always On - Primary Replica و Secondary Replica با Failover👇
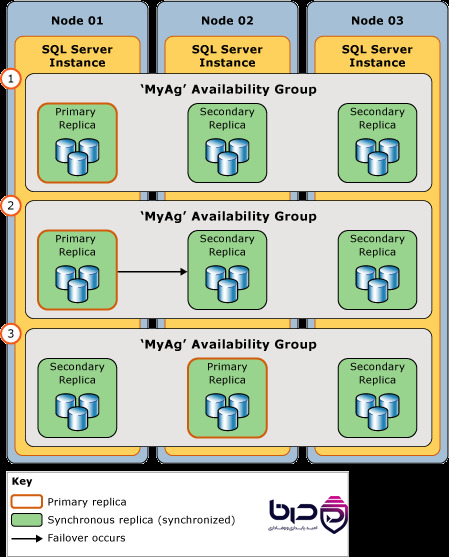
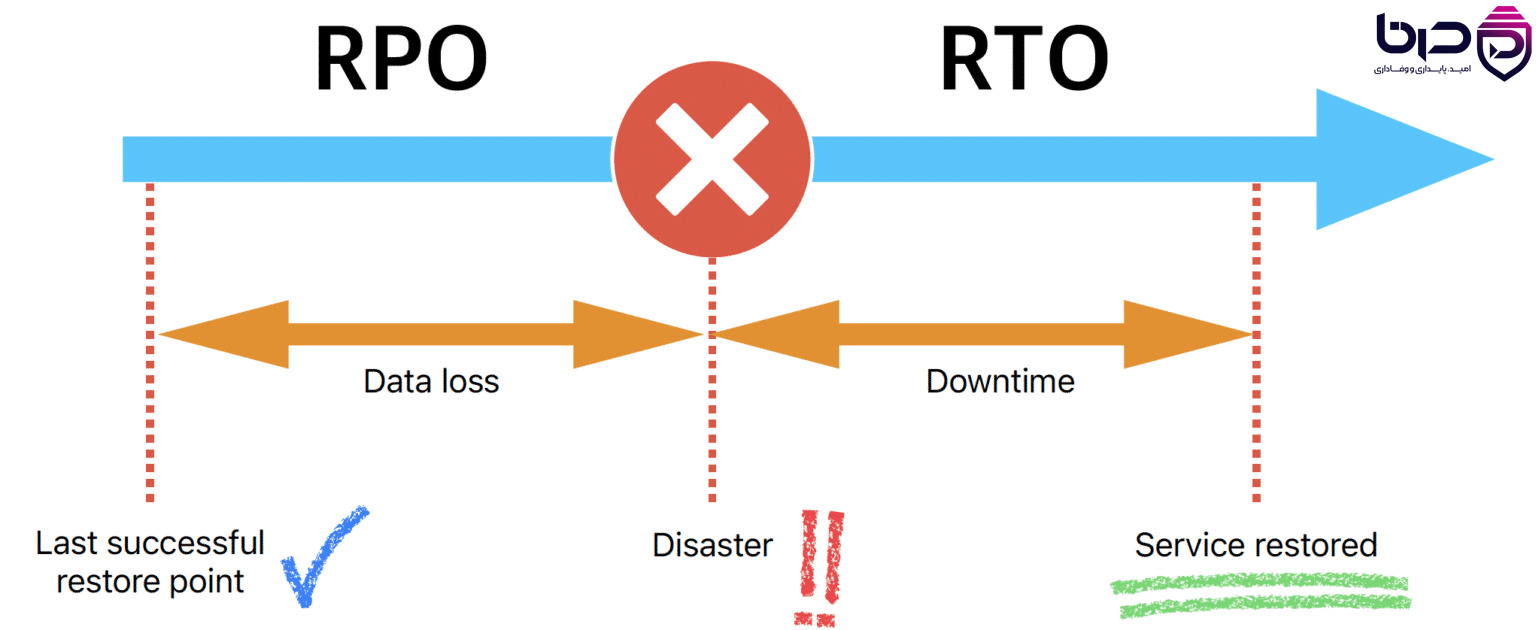
۹. RTO و RPO چه ربطی به HA دارند؟
RTO و RPO شاخصهای کلیدی برای طراحی HA و DR هستند. Azure RPO را بیشینهی میزان قابلقبول از دست رفتن داده و RTO را بیشینهی downtime قابلقبول تعریف میکند. AWS نیز میگوید در disaster recovery planning باید برای هر application بر اساس impact analysis و risk assessment، RTO و RPO تعیین شود. Google Cloud هم تأکید میکند که RTO و RPO معمولاً مبنای طراحی DR و انتخاب strategy هستند.
در عمل، RTO و RPO تعیین میکنند که HA شما باید تا چه حد aggressive باشد. اگر RTO شما چند دقیقه است، active-passive یا active-active با failover خودکار مطرح میشود. اگر RPO نزدیک صفر میخواهید، replication باید بسیار نزدیک و synchronized باشد. بنابراین HA بدون RTO/RPO فقط یک واژهی خوشصداست؛ اما HA با RTO/RPO به design decision واقعی تبدیل میشود.
مثال
یک CRM داخلی ممکن است RPO چند ساعت را تحمل کند، اما یک سیستم تراکنشی مالی شاید RPO نزدیک صفر بخواهد. این تفاوت، architecture backup، replication و failover را بهطور کامل عوض میکند. Azure Site Recovery و AWS DRS هم دقیقاً برای کاهش RTO/RPO در سناریوهای recovery طراحی شدهاند.
RPO vs RTO - Data Loss قبل از Disaster، Downtime بعد از Disaster👇
۱۰. HA و DR چه تفاوت عملی دارند؟
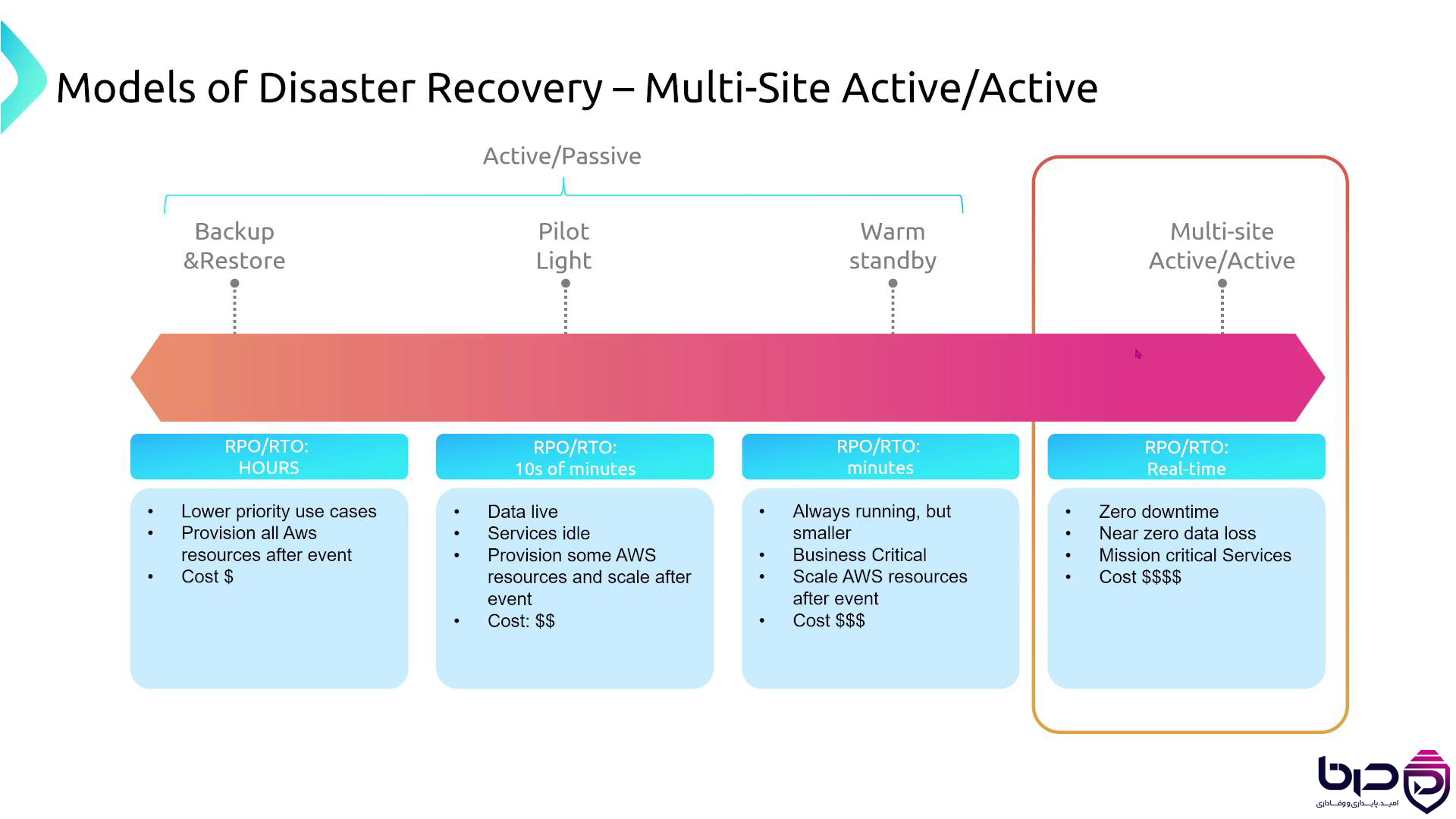
HA برای survive کردن failureهای معمول و کوتاهمدت است؛ DR برای بازسازی سرویس پس از حادثههای بزرگتر. Azure این تفکیک را روشن بیان میکند و میگوید business continuity به HA و DR با هم نیاز دارد. AWS نیز در whitepaperهای DR خود میگوید recovery objectives باید بر اساس impact analysis تعیین شوند و strategyها باید regularly tested شوند.
بنابراین HA را نباید بهجای DR گذاشت. یک system ممکن است بتواند با خرابی یک node یا zone کنار بیاید، اما اگر region اصلی از دست برود، بدون DR واقعی هنوز آسیبپذیر است. در واقع HA در لایهی معماری و عملیات روزمره کار میکند، در حالی که DR برای disaster-level events و بازگشت کامل سرویس است.
۴ مدل Disaster Recovery - Backup Restore تا Multi Site👇
۱۱. Load balancing و health checkها در HA چه نقشی دارند؟
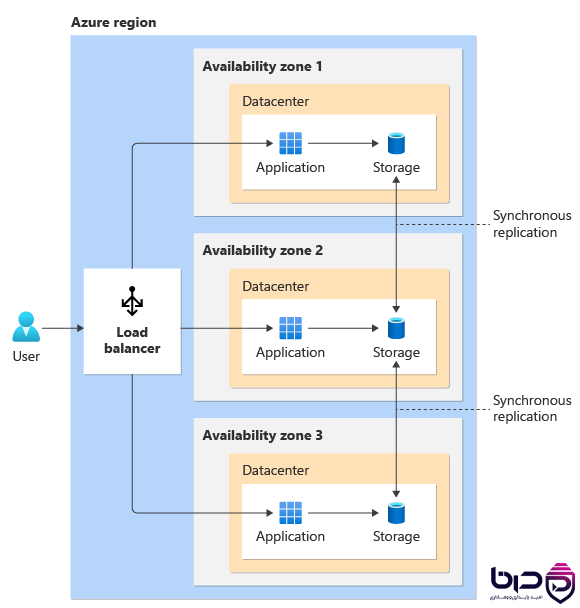
Load balancerها با health check تعیین میکنند کدام backend سالم است و کدام نه. AWS میگوید load balancer به backendهای unhealthy ترافیک نمیفرستد و پس از سالم شدن دوباره به آنها traffic میدهد. Google Cloud هم health checkهای high-fidelity را برای اطمینان از اینکه فقط backendهای آماده receive traffic هستند، بهکار میگیرد. Azure Load Balancer نیز traffic را میان instanceهای سالم توزیع میکند.
در معماری HA، health check فقط یک ping ساده نیست؛ بلکه مکانیزم تصمیمگیری است. اگر health check ضعیف باشد، load balancer ممکن است traffic را به یک backend نیمهخراب بفرستد و تجربهی کاربر خراب شود. اگر too aggressive باشد، backendهای سالم را هم از pool خارج میکند. بنابراین quality of health checks مستقیماً روی quality of availability اثر میگذارد.
مثال
Google Cloud Load Balancing میتواند traffic را به backendهایی در چند region بفرستد و حتی در zonal outage هم خدمت را نگه دارد. این همان جایی است که load balancing از یک component صرفاً performance-oriented به یک component تمامعیار HA تبدیل میشود.
Azure Zone Architecture - Load Balancer به ۳ AZ با Synchronous Replication👇
۱۲. چگونه HA را در عمل طراحی کنیم؟
اول باید failure domainها را شناسایی کنی. دوم باید هر لایهی بحرانی را redundant کنی. سوم باید traffic distribution و failover را خودکار کنی. چهارم باید state را از compute جدا کنی. پنجم باید database و storage را با HA patterns مناسب طراحی کنی. ششم باید RTO/RPO را روشن تعریف کنی. هفتم باید سیستم را بارها تست کنی. این خلاصهای از guidance رسمی AWS، Azure، Google Cloud و Google SRE است.
یک طراحی حرفهای HA معمولاً از edge شروع میشود: DNS resilient، load balancer resilient، app layer redundant، data layer multi-zone، backup and recovery test شده، و observability کامل. AWS میگوید باید availability system را instrument و test کرد و procedureهای manual برای mitigation و recovery آماده داشت. Google Cloud هم به replication در چند zone و region اشاره میکند و Azure نیز zone redundancy و multi-region support را بخشی از reliability capabilities میداند.
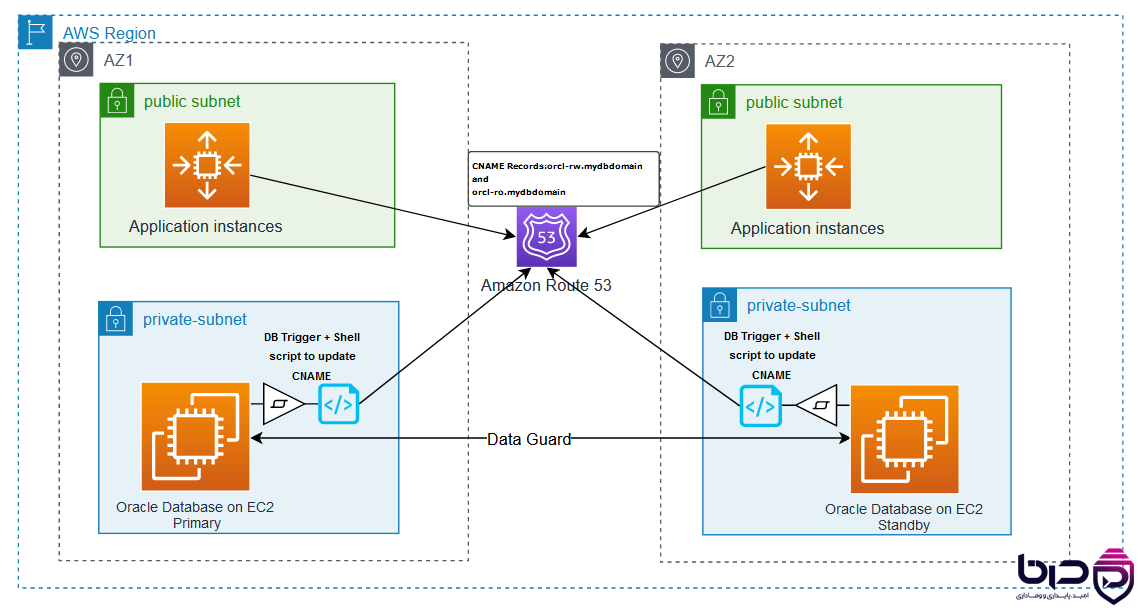
AWS HA Architecture کامل - Route 53، ALB، EC2، RDS و CloudWatch👇
۱۳. چه اشتباهاتی HA را از بین میبرند؟
رایجترین اشتباه، وجود redundancy ظاهری اما failure domain مشترک است. اشتباه دوم، reliance روی manual failover است. اشتباه سوم، وابستگی sessionها یا state به یک node منفرد است. اشتباه چهارم، نبودن test واقعی برای failover و backup restore است. AWS بهصراحت میگوید recovery strategies باید regularly assessed and tested شوند و Google SRE نیز incident response و postmortem را بخشی از reliability practice میداند.
اشتباه مهم دیگر، اشتباه گرفتن SLA provider با HA architecture خودتان است. اینکه سرویس cloud SLA خوبی دارد، به این معنا نیست که workload شما بهصورت خودکار highly available شده است. AWS و Azure هر دو روی shared responsibility و architecture-level design تأکید میکنند.
Single Point of Failure - Gateway Service و DB(SPOF)👇
.png)
۱۴. HA در cloudهای بزرگ چگونه پیاده میشود؟
AWS در Well-Architected و ELB documentation روی multi-AZ load balancing، active-standby یا scalable load-balanced cluster تأکید میکند. Azure روی availability zones، availability sets و load balancing برای resiliency تمرکز دارد و میگوید بعضی services بهصورت خودکار از zone redundancy استفاده میکنند. Google Cloud نیز روی zones، regions، automatic failover و managed load balancing برای HA سرمایهگذاری کرده است.
در دیتابیسها هم همین الگو تکرار میشود: RDS Multi-AZ و Aurora global databases در AWS، Cloud SQL HA و AlloyDB HA در Google Cloud، و Azure database services با automatic failover و standby replica در Azure. این یعنی HA در cloud یک feature واحد نیست؛ مجموعهای از patternهای هماهنگ در compute، network، storage و data است.
15. سوالات متداول FAQ Schema)
Highly Available یعنی چه؟
یعنی سیستم طوری طراحی شده که در برابر خرابیهای روزمره، یک node، یک host، یک zone یا بخشهایی از زیرساخت، همچنان سرویس را حفظ کند یا خیلی سریع بازیابی شود. Azure HA را اینطور تعریف میکند و AWS هم availability را درصد زمانی میداند که workload آمادهی استفاده است.
آیا HA همان Disaster Recovery است؟
خیر. HA برای اختلالات روزمره و جلوگیری از downtime طراحی میشود، اما DR برای بازگشت سرویس پس از disasterهای بزرگتر است. Azure این تفاوت را صریح توضیح میدهد.
مهمترین اصل در طراحی HA چیست؟
حذف single point of failure و توزیع سرویس در failure domainهای مستقل. AWS و Google Cloud هر دو روی این اصل تأکید دارند.
آیا load balancer برای HA لازم است؟
در اغلب سناریوهای عملی بله، چون load balancer traffic را بین backendهای سالم توزیع میکند و از ارسال درخواست به backend خراب جلوگیری میکند. AWS، Azure و Google Cloud همگی این نقش را بهطور رسمی توضیح دادهاند.
RTO و RPO چه نقشی دارند؟
RTO مقدار downtime قابلقبول و RPO مقدار data loss قابلقبول را مشخص میکنند و مستقیماً روی طراحی HA و DR اثر میگذارند. Azure، AWS و Google Cloud این دو معیار را برای طراحی recovery و resilience پایهای میدانند.
Chaos Engineering - Hypothesis، Experiment، Injection، Observation، Analysis و Learning👇
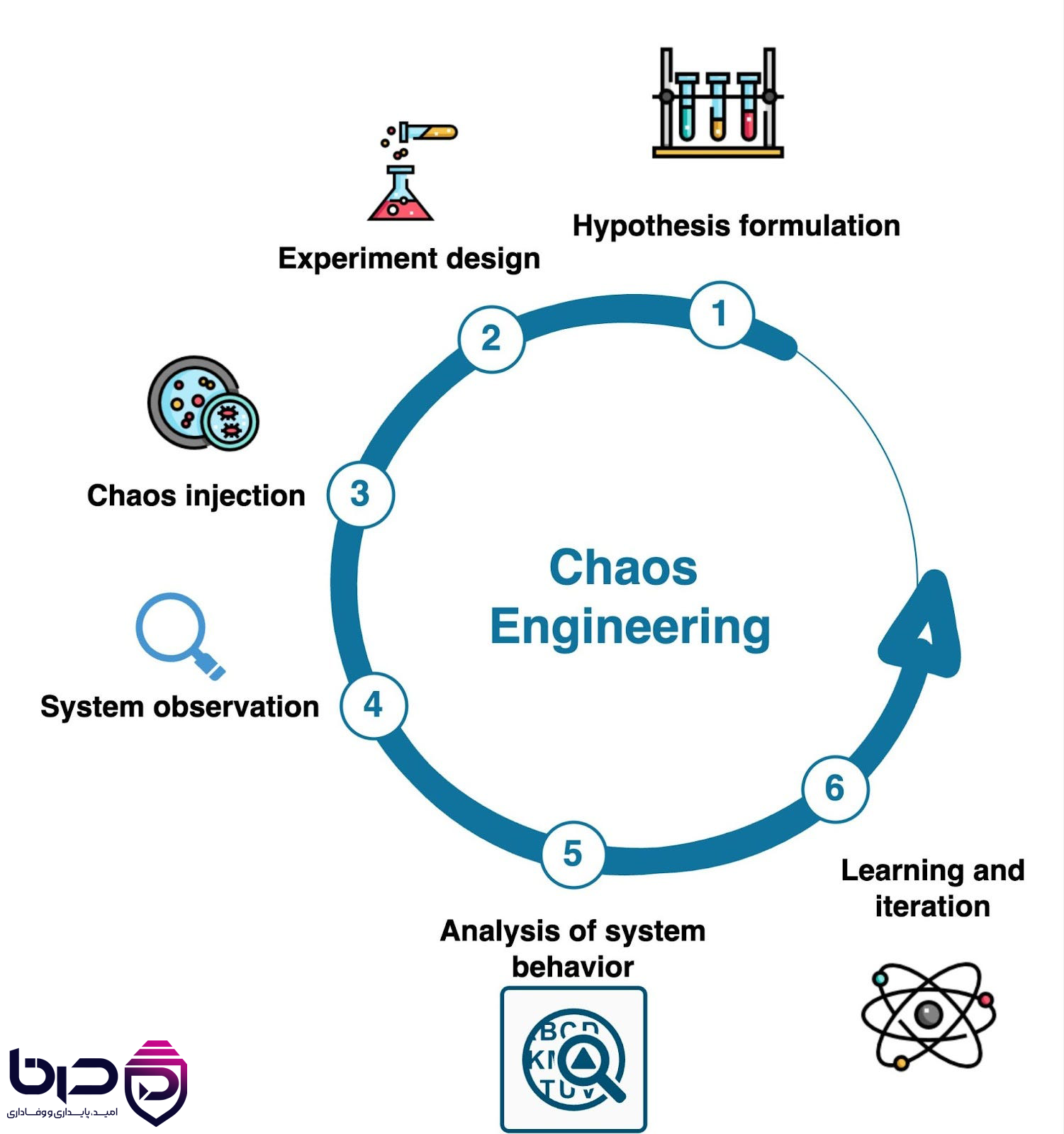
16. جمعبندی
- طراحی سیستمهای highly available یعنی پذیرفتن این واقعیت که failure رخ میدهد، اما نباید به outage تبدیل شود. Azure HA را resilience در برابر مشکلات روزمره میداند، AWS availability را درصد زمانی میداند که workload باید وظیفهی خود را انجام دهد، و Google Cloud میگوید برای HA باید سرویسها را در چند zone و region replicate و failover خودکار را فعال کرد. این سه نگاه، در اصل یک حقیقت را تأیید میکنند: HA یک property معماری است، نه یک checkbox.
- اگر بخواهیم خیلی دقیق جمعبندی کنیم، سیستم highly available سیستمی است که با redundancy درست، failure domainهای جدا، load balancing سالم، state management هوشمند، database resilient، failover خودکار، RTO/RPO روشن و testهای منظم ساخته شده باشد. چنین سیستمی نه فقط برای «کمتر down شدن» بلکه برای حفظ اعتماد کاربر، تداوم کسبوکار و سرعت تحویل خدمات طراحی میشود. به همین دلیل است که HA در عمل، فقط یک ویژگی فنی نیست؛ یک مزیت رقابتی واقعی است.