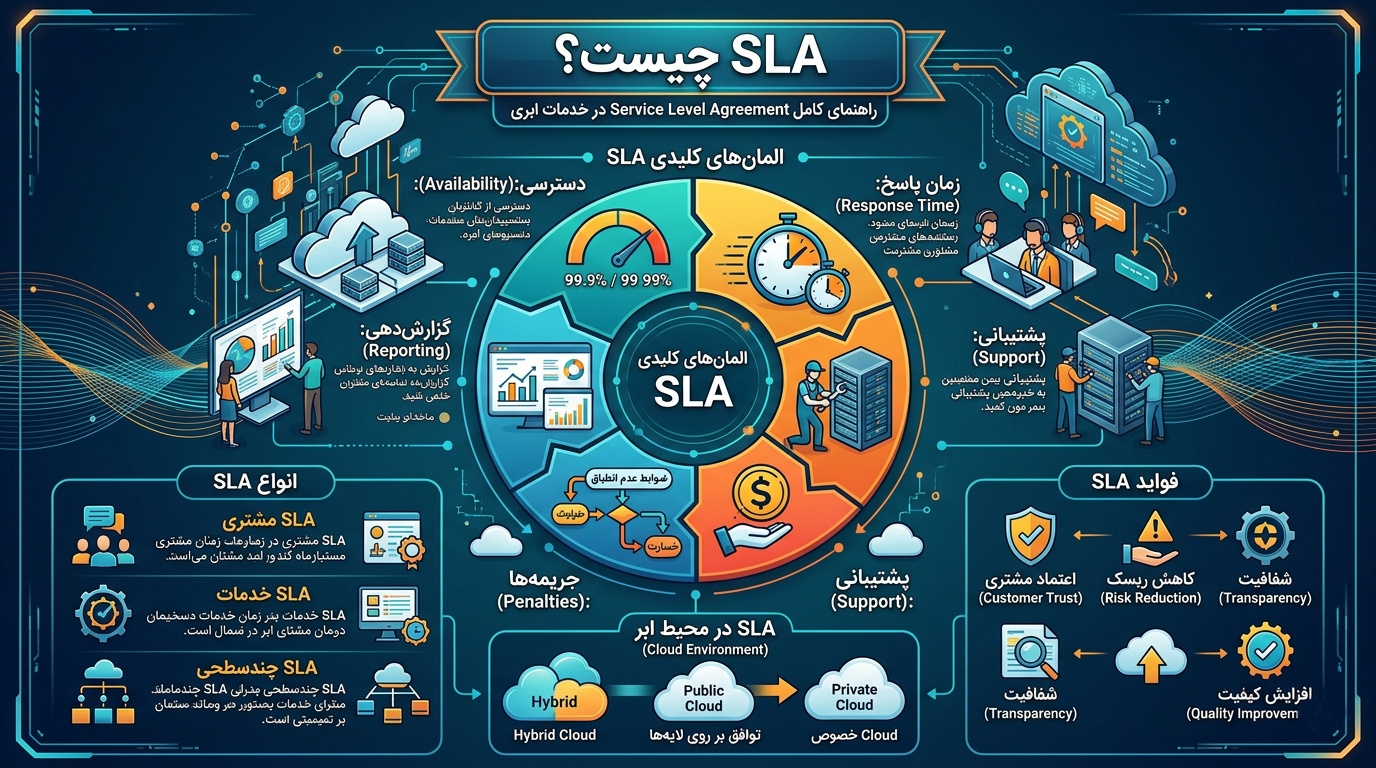
در دنیای خدمات ابری، فقط اینکه یک سرویس «کار کند» کافی نیست. سازمانها، استارتاپها و تیمهای فنی به یک تعهد روشن نیاز دارند که مشخص کند سرویس تا چه حد در دسترس خواهد بود، در چه شرایطی قابلقبول محسوب میشود، اگر service level رعایت نشود چه اتفاقی میافتد، و مسئولیت هر طرف دقیقاً چیست. اینجاست که SLA یا Service Level Agreement وارد میشود؛ یعنی قرارداد سطح خدمت بین ارائهدهنده و مشتری که حداقلهای قابلانتظار را مشخص میکند و در صورت عدم تحقق، پیامدهای قراردادی مثل service credit را تعریف میکند. Microsoft SLA را بهصراحت یک commitment قراردادی با consequences مشخص برای targets برآوردهنشده معرفی میکند.
اگر هنوز با فلسفه DevOps و نقش آن در پایداری سرویسها آشنا نیستید، پیشنهاد میکنیم ابتدا مقاله «DevOps چیست؟ راهنمای کامل از صفر تا حرفهای (۲۰۲۶)» را مطالعه کنید تا بهتر متوجه شوید SLA در چه مدل عملیاتی معنا پیدا میکند.
در فضای cloud، SLA فقط یک بند حقوقی نیست؛ یک ابزار معماری و عملیاتی هم هست. وقتی شما روی یک سرویس ابری بنا میگذارید، عملاً بخشی از ریسک availability، connectivity، durability و recovery را به provider میسپارید. اما این سپردن، کورکورانه نیست؛ چون SLA دقیقاً تعریف میکند provider چه چیزی را تضمین میکند، چه چیزهایی را تضمین نمیکند، و اگر اتفاقی افتاد، چه جبرانی وجود دارد. NIST نیز در بحث procurement سرویسهای ابری تأکید میکند که SLAها باید requirements شفاف و measurable داشته باشند تا delivery و remedies قابلسنجش باشند.
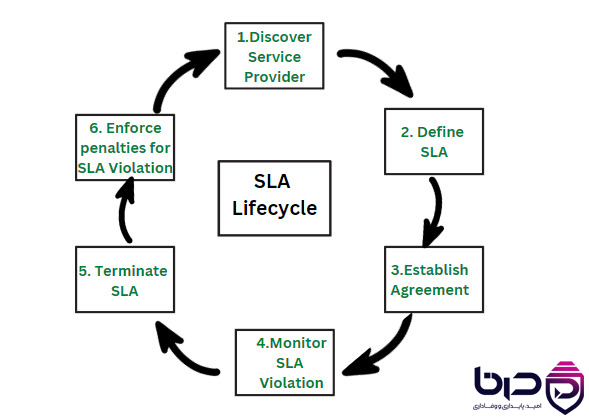
چرخه حیات SLA - Discover، Define، Establish، Monitor، Terminate و Enforce👇
۱. SLA دقیقاً چیست؟
SLA مخفف Service Level Agreement است؛ یعنی توافقنامهای که سطح خدمت، معیارهای آن، نحوهی اندازهگیری و پیامدهای عدم تحقق آن را مشخص میکند. در cloud، این توافق معمولاً میان provider و customer امضا یا بهصورت قراردادی پذیرفته میشود و روی موضوعاتی مثل uptime، response time، connectivity، support، service credits و scope of responsibility تمرکز دارد. Azure بهصراحت میگوید SLA یک commitment برای uptime و connectivity است و برای برخی خدمات، service credit هم تعریف میکند.
مثال ساده
فرض کن شما یک وباپلیکیشن مالی روی Cloud اجرا میکنی. اگر provider اعلام کند که یک سرویس خاص 99.95% uptime دارد، یعنی از نظر قراردادی انتظار میرود آن سرویس تقریباً همیشه در دسترس باشد و اگر این حداقل رعایت نشود، customer میتواند مطابق SLA از service credit استفاده کند. Google Cloud برای بسیاری از سرویسهایش دقیقاً چنین چارچوبی دارد و در SLAهای رسمی، Monthly Uptime Percentage و Financial Credits را مشخص میکند.
۲. SLA در cloud چرا اینقدر مهم است؟
در onpremise، اگر یک سرور خراب شود، سازمان معمولاً خودش مسئول همهچیز است: سختافزار، برق، شبکه، storage، backup و recovery. اما در cloud، بخشی از این مسئولیت میان شما و provider تقسیم میشود. SLA این مرز مسئولیت را شفاف میکند. NIST در راهنمای metrics برای cloud میگوید که مقایسهی سرویسهای cloud ساده نیست و باید با معیارهای قابلاندازهگیری و SLAهای مناسب، delivery و remedies را ارزیابی کرد.
مثال واقعی
اگر یک کسبوکار ecommerce روی یک سرویس cloud بنا شده باشد و در طول یک ماه downtime رخ دهد، SLA تعیین میکند آیا این downtime صرفاً یک مشکل عملیاتی است یا تخطی قراردادی. اگر تخطی رخ داده باشد، service credit میتواند بخشی از هزینهی پرداختشده را جبران کند. Azure و Google Cloud هر دو در SLAهای رسمی خود این مفهوم را با service credit یا financial credit توضیح میدهند.
SLA Requirements - Uptime Guarantees، Penalties، Exclusions، Provider Liability و Disaster Recovery👇

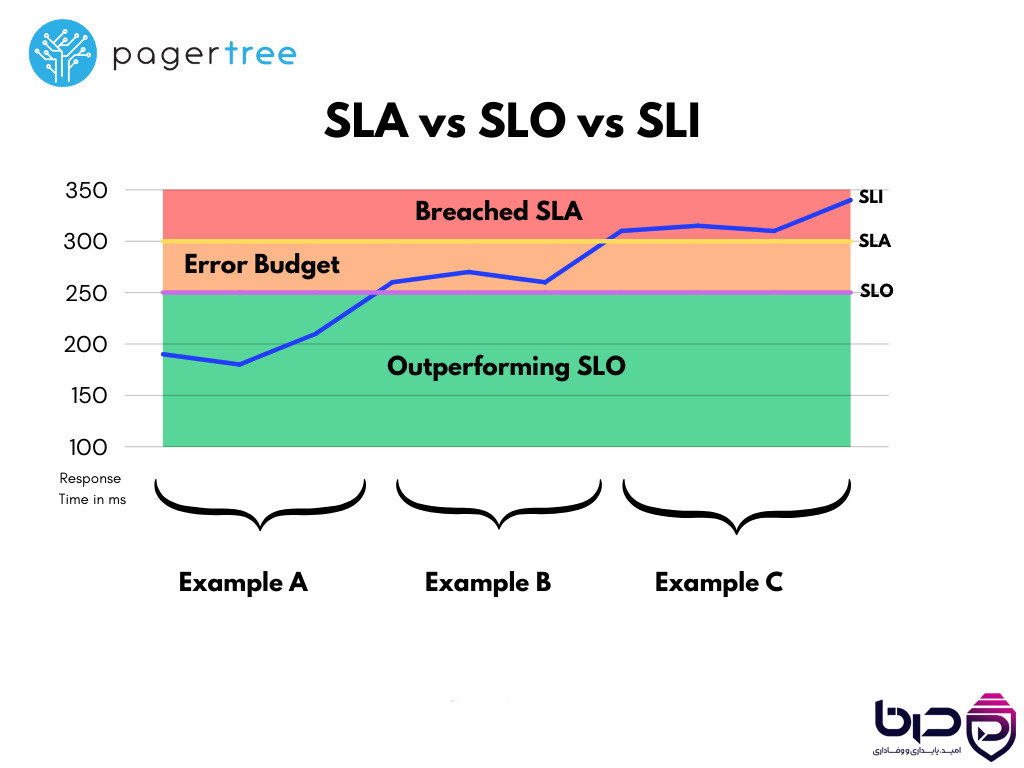
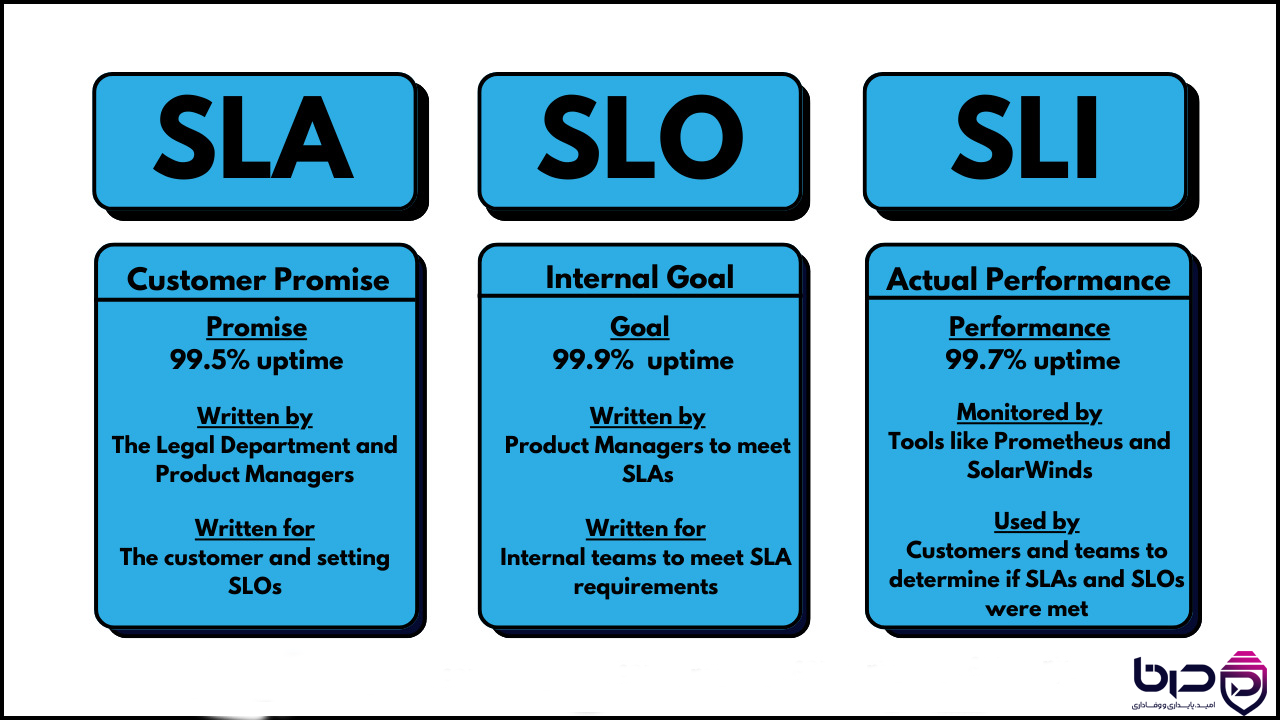
۳. SLA، SLO و SLI چه فرقی دارند؟
این سه واژه خیلی وقتها با هم قاطی میشوند، اما در cloud هر کدام نقش مشخصی دارند. Microsoft تفاوت آنها را خیلی شفاف توضیح میدهد: SLA تعهد قراردادی بین provider و customer است، SLO هدف داخلی reliability برای workload شماست، و SLA را نباید بدون فکر بهعنوان هدف داخلی خودتان کپی کنید. Microsoft همچنین تأکید میکند که SLO باید با توجه به code، dependencyها، فرایندهای عملیاتی و tolerance کاربران نسبت به downtime تنظیم شود.
اگر هنوز با اینکه چگونه تحویل نرمافزار میتواند روی پایداری سرویس اثر بگذارد آشنا نیستید، پیشنهاد میکنیم مقاله «CI/CD در ۲۰۲۶؛ از صفر تا دیپلوی بدون قطعی» را بخوانید تا بهتر ببینید چرا release stability بخشی از reliability واقعی است.
مثال عملی
SLA: Provider میگوید سرویس storage ممکن است 99.95% available باشد.
SLO: تیم شما تصمیم میگیرد سیستم باید در عمل 99.99% reliable باشد.
SLI: شاخص اندازهگیری واقعی، مثلاً درصد درخواستهای موفق یا میزان latency واقعی.
چرا این تفکیک مهم است؟
چون ممکن است SLA یک سرویس cloud برای شما کافی نباشد. مثلاً اگر چند سرویس cloud را به هم زنجیر کرده باشید، availability نهایی سیستم شما از availability تکتک سرویسها پایینتر میشود. Microsoft صریحاً هشدار میدهد که بعضی وقتها به SLO سختگیرانهتری از SLA provider نیاز دارید.
نمودار SLA vs SLO vs SLI - Outperforming SLO، Error Budget و Breached SLA👇
۴. یک SLA ابری از چه بخشهایی تشکیل میشود؟
SLA در cloud فقط یک عدد uptime نیست. معمولاً چند بخش اصلی دارد: تعریف service، محدودهی پوشش، روش اندازهگیری، بازهی زمانی اندازهگیری، شرایط استثنا، service credit، روش درخواست جبران، و مسئولیتهای customer. AWS میگوید SLAهایش برای services paid و generally available ارائه میشوند و برای هر account بهصورت جداگانه اعمال میشوند. Azure نیز میگوید SLA علاوه بر uptime، procedureهای service credit و تعریف availability را شامل میشود.
مثال
در Cloud Storage گوگل، SLA مشخص میکند که برای هر class و region چه Monthly Uptime Percentageای انتظار میرود، چه چیزی covered service محسوب میشود، و اگر SLO برآورده نشود، چه Financial Creditی ارائه میشود. این یعنی SLA هم technical است، هم operational و هم مالی.
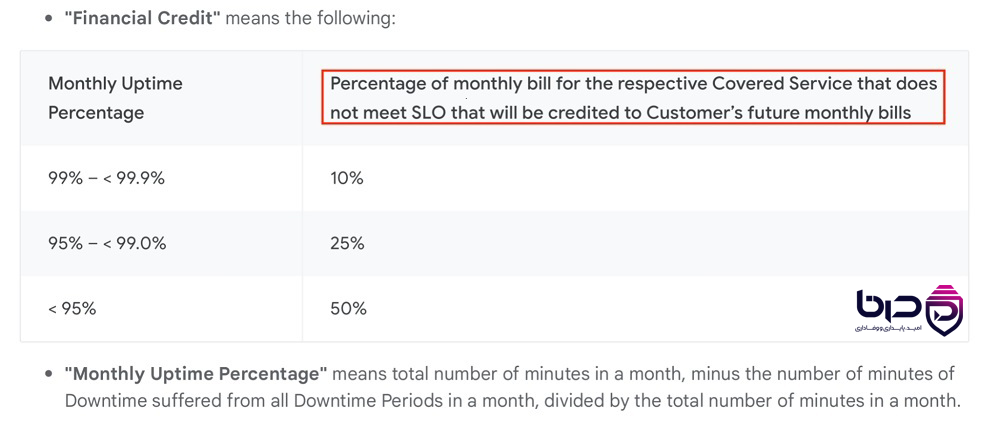
Financial Credit در SLA - Monthly Uptime Percentage و درصد Credit👇
۵. uptime در SLA دقیقاً یعنی چه؟
یکی از رایجترین معیارها در SLA، Monthly Uptime Percentage است. این معیار مشخص میکند یک سرویس در طول ماه چه درصدی از زمان در دسترس بوده است. Google Cloud در SLAهای متعدد خود این مفهوم را بهعنوان SLO تعریف میکند و برای سرویسهایی مثل Pub/Sub، Cloud CDN و Cloud Storage مقادیر دقیق ارائه میدهد؛ برای مثال Pub/Sub برای برخی حالتها 99.95% و Cloud CDN نیز 99.95% را بهعنوان SLO ذکر میکند.
اگر هنوز با observability و نقش آن در اندازهگیری دقیق availability و latency آشنا نیستید، پیشنهاد میکنیم ابتدا مقاله «Prometheus و Grafana چیست؟ راهنمای کامل Observability در Cloud-Native» را مطالعه کنید تا بهتر متوجه شوید SLI و SLO چگونه بهصورت عملی اندازهگیری میشوند.
مثال فنی
اگر یک سرویس 99.95% uptime داشته باشد، روی کاغذ بسیار پایدار است؛ اما در سیستمهای ترکیبی، این عدد بهتنهایی کافی نیست. اگر اپلیکیشن شما از چند سرویس وابسته تشکیل شده باشد، availability نهایی پایینتر از هر سرویس منفرد خواهد بود. به همین دلیل Microsoft هشدار میدهد که SLA provider را نباید بیچونوچرا بهعنوان SLO داخلی پذیرفت.
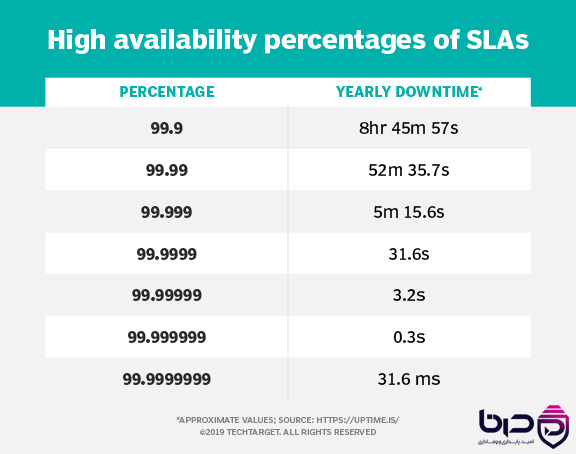
High Availability Percentages - ۹۹.۹ تا ۹۹.۹۹۹۹۹۹۹۹ و Yearly Downtime مربوطه👇
۶. Service Credit چیست و چرا مهم است؟
Service credit یا financial credit همان جبرانی است که provider وقتی SLA را برآورده نمیکند به customer میدهد. این جبران معمولاً بهصورت درصدی از bill آینده اعمال میشود و هدفش این است که تخطی از SLA فقط یک failure فنی نباشد، بلکه پیامد قراردادی هم داشته باشد. Azure بهوضوح میگوید SLA شامل procedure دریافت service credit است و همین بخش، نقش enforcement policy را بازی میکند. Google Cloud هم در SLAهای Cloud Storage، درصدهای credit را بسته به میزان عدم تحقق SLO مشخص میکند.
مثال واقعی
در Cloud Storage گوگل، اگر service به SLO نرسد، credit میتواند بسته به میزان افت uptime از 10% تا 50% bill را پوشش دهد. این نشان میدهد که SLA فقط یک statement تئوریک نیست، بلکه ابزار مالی و قراردادی هم هست.
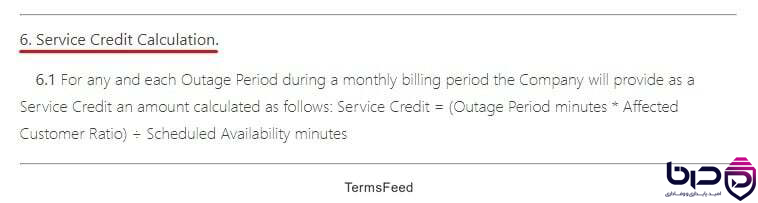
فرمول Service Credit Calculation - Outage Period × Affected Customer Ratio ÷ Scheduled Availability👇
۷. SLA در AWS، Azure و Google Cloud چه شکلی دارد؟
AWS اعلام میکند که برای تمام خدمات paid و generally available، SLA ارائه میدهد. این یعنی اگر یک سرویس وارد production عمومی شده باشد، AWS برای آن تعهد سطح خدمت دارد. برای مثال Amazon EC2 دارای SLA اختصاصی است که برای هر account بهصورت جداگانه اعمال میشود.
Azure هم میگوید SLAهایش تعهد Microsoft برای uptime و connectivity هستند و برای برخی سرویسها متفاوتاند. نکتهی مهم این است که Azure در مستندات reliability خود توضیح میدهد که SLA علاوه بر تعهد uptime، procedure service credit و definitionهای availability را نیز در بر میگیرد.
Google Cloud نیز یک repository مرکزی برای SLAهای سرویسهای مختلف دارد؛ از Cloud Storage و Pub/Sub گرفته تا Cloud CDN و Cloud SQL و بسیاری سرویسهای دیگر. در این SLAها معمولاً Monthly Uptime Percentage، SLO و Financial Credit بهصورت دقیق تعریف میشود.
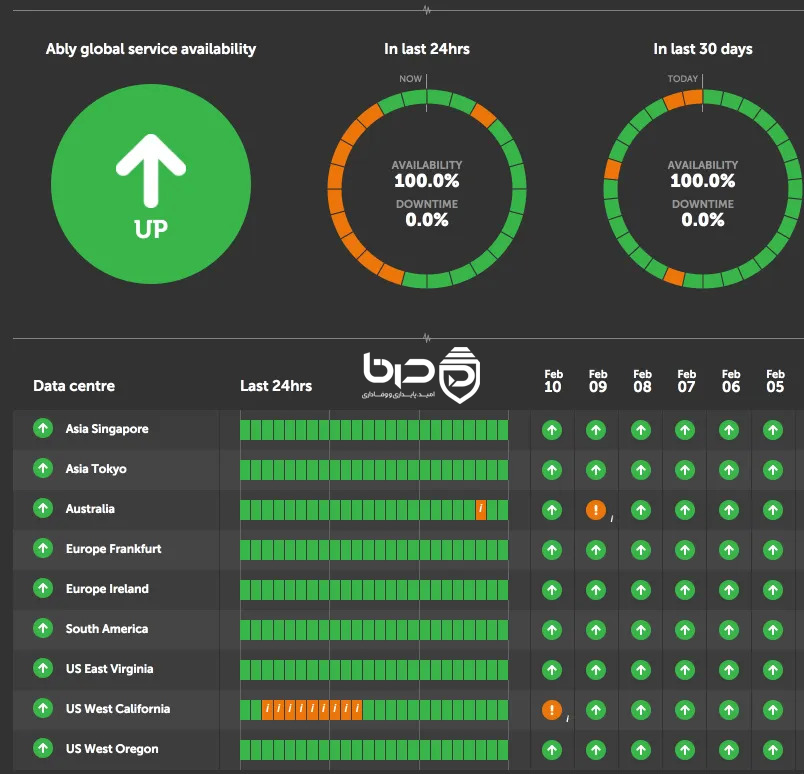
داشبورد Availability Ably - ۱۰۰ uptime در ۲۴ ساعت و ۳۰ روز گذشته👇
۸. چرا SLA در cloud فقط مسئلهی فنی نیست؟
SLA روی business، finance و risk management هم اثر مستقیم دارد. وقتی تیم شما یک سرویس ابری را انتخاب میکند، در واقع دارد بخشی از ریسک availability را به provider منتقل میکند. NIST هم همین را در قالب procurement توضیح میدهد: SLA باید requirements، performance و remedies را بهصورت measurable پوشش دهد تا تصمیمگیری خرید cloud فقط بر اساس تبلیغات نباشد.
اگر هنوز با نقش بکاپ و بازیابی در تداوم سرویس آشنا نیستید، پیشنهاد میکنیم مقاله «بکاپگیری در DirectAdmin؛ آموزش کامل و ساده» را مطالعه کنید تا بهتر متوجه شوید recovery بخشی از مدیریت واقعی reliability است.
مثال
اگر یک بانک آنلاین downtime داشته باشد، فقط یک مشکل فنی رخ نداده؛ اعتماد مشتری، عملیات مالی، reputation و حتی compliance هم تحتتأثیر قرار میگیرند. در چنین فضایی، SLA ابزاری است که به business میگوید این سرویس چه سطحی از اطمینان را واقعاً تضمین میکند. به همین دلیل، مدیر فنی، مدیر محصول و تیم حقوقی باید SLA را با هم بخوانند، نه جداگانه.
۹. SLA چگونه اندازهگیری میشود؟
SLA معمولاً بر اساس بازههای زمانی مشخص، مثل ماه تقویمی، اندازهگیری میشود. Google Cloud در SLAهایش بارها تأکید میکند که Monthly Uptime Percentage، Financial Credit و SLOها بر مبنای calendar month و per project / per region محاسبه میشوند. Cloud Storage حتی تعریف میکند که error rate و valid requests چگونه محاسبه میشوند.
مثال
اگر یک سرویس در بخشی از ماه قطع شود، ارائهدهنده فقط مجموع زمان قطعشدن را نمیسنجد؛ بلکه این downtime را با چارچوب خاص SLA آن سرویس میسنجد. ممکن است بعضی رویدادها خارج از scope باشند یا فقط در شرایط خاص قابلمحاسبه باشند. همین جزئیات است که باعث میشود خواندن SLA بدون دقت، خیلی خطرناک باشد.
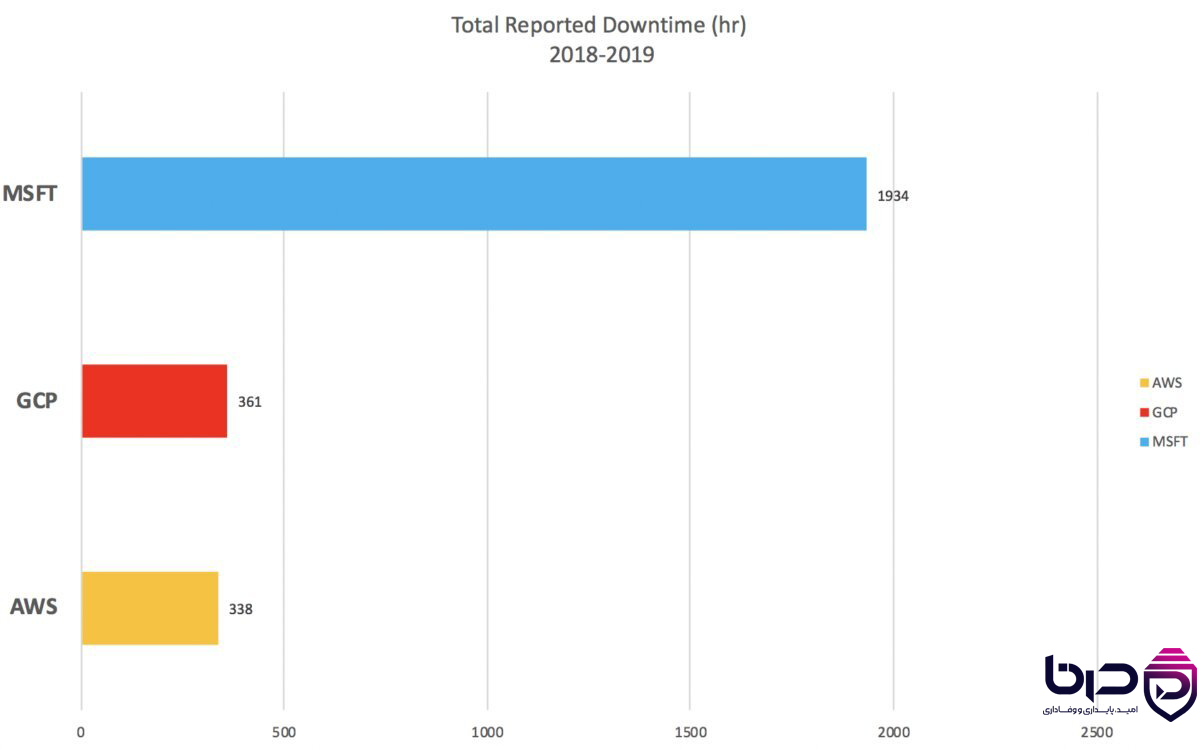
مقایسه Downtime Cloud Providers AWS ۳۳۸ ساعت، GCP ۳۶۱ ساعت، MSFT ۱۹۳۴ ساعت👇
۱۰. SLA در cloud چه چیزی را تضمین نمیکند؟
SLA معمولاً همهچیز را تضمین نمیکند. تضمین آن محدود به scope، شرایط، region، service tier و استثناهای قرارداد است. برای مثال، Google Cloud در SLAهای خودش servicespecific scope و شرایط دقیق انتخاب service class و region را مشخص میکند. Azure هم میگوید SLAهای سرویسها با هم فرق دارند و حتی درون یک service ممکن است productهای مختلف SLAهای متفاوتی داشته باشند.
مثال
ممکن است یک cloud provider برای storage regionی خاص SLA بسیار خوب ارائه دهد، اما برای storage class یا location دیگر درصد پایینتری بدهد. Cloud Storage گوگل دقیقاً چنین تفاوتهایی را در کلاسهای مختلف storage و regionهای مختلف نشان میدهد. بنابراین SLA همیشه باید در context همان service، همان region و همان tier خوانده شود.
۱۱. چطور SLA مناسب را برای یک سرویس ابری بخوانیم؟
خواندن SLA باید از روی سؤالهای درست شروع شود. اول باید ببینی service covered دقیقاً چیست. بعد باید بررسی کنی uptime چگونه تعریف شده، چه استثناهایی دارد، service credit چگونه محاسبه میشود، و آیا service واقعاً برای workload تو کافی هست یا نه. Microsoft بهصراحت میگوید SLA را باید برای informing SLO خواند، نه برای کپیکردن کورکورانهی عدد uptime آن.
مثال عملی
اگر یک سامانهی فروش بلیت داری، availability دیتابیس، queue، storage و gateway همگی مهماند. ممکن است هر کدام SLA جداگانه داشته باشند، اما availability نهایی سیستم تو از ترکیب اینها کمتر است. پس باید SLAها را با معماری واقعی سیستم match کنی، نه صرفاً با صفحهی marketing provider.
۱۲. SLA و معماری high availability چه رابطهای دارند؟
SLA فقط تعهد provider است، اما high availability تعهد معماری شماست. یعنی حتی اگر provider uptime بالایی بدهد، شما هنوز باید workload را بهصورت resilient طراحی کنید. Microsoft در guidance reliability میگوید SLA provider تنها بخشی از reliability موردنیاز است و باید به code، dependencyها و tolerance کاربران هم توجه کرد. به بیان ساده، SLA خوب بدون architecture خوب کافی نیست.
اگر هنوز با امنسازی سیستمعامل و کاهش سطح حمله آشنا نیستید، پیشنهاد میکنیم مقاله «OS Hardening چیست؟ راهنمای جامع امنسازی سیستمعامل در ۲۰۲۶» را بخوانید تا بهتر ببینید reliability فقط به SLA provider وابسته نیست.
مثال
اگر اپلیکیشن تو فقط یک database instance داشته باشد، یک cache واحد و یک region واحد، حتی با SLA خوب provider هم ممکن است در برابر failure آسیبپذیر بمانی. اما اگر multizone، backup، health check و failover داشته باشی، میتوانی از SLA provider بهتر استفاده کنی و SLO واقعی بالاتری بسازی. همین تفاوت، مرز بین استفادهی عادی و استفادهی حرفهای از cloud است.
۱۳. SLA در خدمات ابری چه خطاهای ذهنی رایجی دارد؟
یکی از خطاهای رایج این است که افراد فکر میکنند SLA یعنی «هیچوقت قطعی نداریم». این برداشت غلط است. SLA یعنی provider یک حداقل تعهد تعریف کرده و اگر به آن نرسد، جبران مشخصی وجود دارد. NIST هم روی این نکته تأکید دارد که SLA باید measurable باشد و remedies را شفاف کند، نه اینکه وعدهی مطلق و غیرواقعی بدهد.
مثال
یک service با 99.95% uptime هنوز هم میتواند downtime داشته باشد؛ فقط مقدار و شرایط آن محدود شده است. بنابراین تصمیمگیری حرفهای این نیست که بگویی «SLA دارد، پس خیالم راحت است»، بلکه این است که ببینی این SLA برای workload تو کافی هست یا باید redundancy و architecture را هم تقویت کنی.
۱۴. بهترین practiceها برای استفاده از SLA در cloud
اول، SLA را با SLOهای داخلی خودت مقایسه کن، نه اینکه همان عدد را کورکورانه قبول کنی. دوم، همهی سرویسهای وابسته را با هم ببین، چون availability نهایی سیستم ترکیبی از آنهاست. سوم، service credit را فقط بهعنوان جبران مالی نبین؛ آن را نشانهی این بدان که قرارداد، operational expectation را مشخص کرده است. چهارم، region، tier و service class را دقیق بخوان، چون SLAها در cloud بین اینها متفاوتاند. اینها همه از مستندات Microsoft، AWS و Google Cloud بهوضوح قابل برداشتاند.
مثال
یک تیم DevOps ممکن است برای storage به SLA خیلی خوبی برسد، اما اگر DNS، load balancer یا CI/CD pipeline SLA ضعیفتری داشته باشند، اختلال عملیاتی همچنان رخ میدهد. پس SLAها را بهصورت اکوسیستمی بخوان، نه سرویسبهسرویس جدا.
15. سوالات متداول (FAQ Schema)
SLA دقیقاً چیست؟
SLA یا Service Level Agreement قراردادی است که سطح خدمت، نحوهی اندازهگیری آن، و پیامدهای عدم تحقق را مشخص میکند. در cloud معمولاً روی uptime، connectivity، service credit و scope تمرکز دارد.
تفاوت SLA و SLO چیست؟
SLA تعهد قراردادی provider است، اما SLO هدف داخلی reliability برای workload شماست. Microsoft توصیه میکند SLA را برای inform کردن SLO استفاده کنید، نه برای کپیکردن مستقیم آن. ([learn.microsoft.com]
آیا SLA یعنی سرویس هیچوقت قطع نمیشود؟
خیر. SLA معمولاً سطحی از availability را تضمین میکند و اگر service به آن نرسد، service credit یا financial credit تعریف میشود.
آیا همه سرویسهای cloud SLA دارند؟
AWS اعلام میکند برای همه سرویسهای paid و generally available SLA ارائه میدهد. Google Cloud هم برای تعداد زیادی از سرویسها SLAهای رسمی منتشر کرده است.
SLA برای چه کسانی مهمتر است؟
برای همهی تیمهای فنی و business مهم است، اما مخصوصاً برای workloadهای حساس مثل ecommerce، finance، SaaS، healthcare، و سامانههایی که downtime برایشان هزینهی مستقیم دارد. این همان جایی است که SLA از یک سند حقوقی به یک ابزار تصمیمگیری معماری تبدیل میشود.
SLA vs SLO vs SLI - Customer Promise، Internal Goal و Actual Performanc👇
16. جمعبندی
- SLA در خدمات ابری فقط یک بند قراردادی نیست؛ یک نقشهی دقیق از مسئولیت، reliability، uptime، service credit و scope سرویس است. Azure آن را commitmentی برای uptime و connectivity میداند، AWS برای همهی سرویسهای paid و generally available SLA ارائه میکند، Google Cloud برای سرویسهای مختلف از Cloud Storage تا Pub/Sub و Cloud CDN، SLO و Financial Credit را مشخص میکند، و NIST هم تأکید دارد که cloud SLA باید measurable باشد و remedies را روشن کند.
- اگر بخواهیم خیلی روشن بگوییم، SLA در cloud زبان مشترک business و engineering است. business از آن برای فهم ریسک و جبران استفاده میکند، engineering از آن برای طراحی SLO و architecture بهتر بهره میبرد، و procurement از آن برای مقایسهی واقعی serviceها کمک میگیرد. در دنیای cloud، SLA فقط «چه چیزی قول داده شده» نیست؛ بلکه «چطور باید آن را اندازه گرفت، چه زمانی شکست محسوب میشود، و چه جبرانی وجود دارد» را هم مشخص میکند.