
اگر بخواهیم صادق باشیم، دنیای توسعه نرمافزار در سالهای اخیر دیگر شبیه گذشته نیست. روزی بود که تیمها یک نسخه را میساختند، تست میکردند، بهدقت deploy میکردند و بعد از انتشار، تازه به فکر امنیت میافتادند. اما امروز همهچیز با سرعت بسیار بالاتری پیش میرود: releaseهای مداوم، microserviceها، cloudnative architecture، CI/CD، GitOps و البته رشد خیرهکننده ابزارهای AI برای تولید کد. این سرعت، اگرچه بهرهوری را بالا برده، اما یک مشکل جدی هم بهوجود آورده است: آسیبپذیریها هم سریعتر از قبل تولید میشوند.
در چنین فضایی، دیگر نمیشود امنیت را بهعنوان یک مرحلهی جداگانه در انتهای پروژه دید. اگر امنیت را بعد از merge، بعد از test و بعد از deploy بررسی کنیم، عملاً داریم با تاخیر بهدنبال مشکلی میگردیم که قبلاً وارد سیستم شده است. این همان نقطهای است که ابزارهای مدرن SAST وارد میشوند. اما همه ابزارهای SAST یکسان نیستند. بعضی از آنها بسیار سنگیناند، بعضی دیگر rulewriting پیچیدهای دارند، بعضیها false positive زیادی تولید میکنند و برخی هم آنقدر کند هستند که در عمل، تیم توسعه آنها را دور میزند.
اگر هنوز با مفهوم DevOps و نقش آن در سرعت و کیفیت توسعه آشنا نیستید، پیشنهاد میکنیم مقاله «DevOps چیست» را مطالعه کنید تا درک بهتری از جایگاه امنیت در این چرخه داشته باشید.
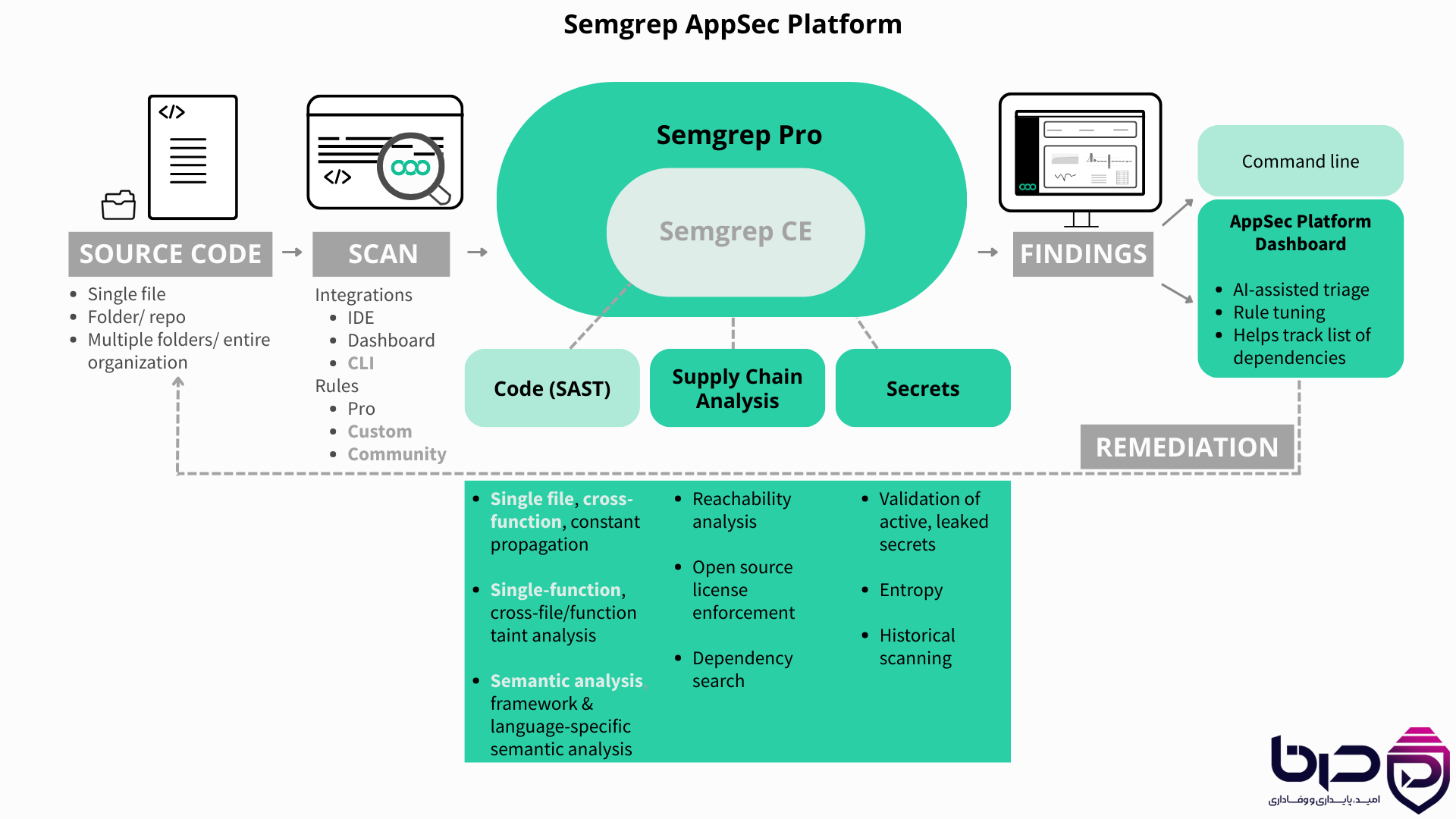
Semgrep دقیقاً در همین نقطه درخشیده است. Semgrep یک ابزار تحلیل استاتیک کد است که با رویکردی متفاوت از ابزارهای سنتی کار میکند. بهجای اینکه شما را وادار کند درگیر query languageهای پیچیده، AST patternهای دشوار یا تنظیمات سنگین شوید، Semgrep ruleهایی به شما میدهد که بسیار شبیه خود کد هستند. همین سادگی ظاهری، در واقع یکی از بزرگترین قدرتهای آن است. توسعهدهنده میتواند rule را بخواند، بفهمد، بنویسد و در repository نگهداری کند؛ درست مثل هر فایل کد دیگری. مستندات رسمی Semgrep هم تأکید میکنند که این پلتفرم امروز فقط SAST نیست، بلکه SCA و secrets detection را هم در یک جریان واحد ارائه میدهد. semgrep.dev1
اما Semgrep در سال ۲۰۲۶ فقط یک scanner هوشمند نیست؛ به یک لایهی جدی AppSec تبدیل شده است. نسخه Community Edition برای اسکن سریع و سبک مناسب است، اما Semgrep AppSec Platform و Semgrep Code قابلیتهای عمیقتری دارند: crossfile analysis، crossfunction analysis، triage و remediation، AIpowered detection برای باگهای پیچیده مثل IDOR و broken authorization، Autofix برای ساخت PR اصلاحی، و حتی MCP plugin برای ابزارهای AI coding مانند Cursor و Claude Code. این یعنی Semgrep تلاش کرده امنیت را از یک ابزار جداگانه، به بخشی از فرایند روزمرهی توسعه تبدیل کند.
این تغییر، از نظر فرهنگی هم مهم است. چون مشکل امنیت در تیمهای توسعه معمولاً «نبود ابزار» نیست؛ مشکل، «فرآیند» است. خیلی از تیمها ابزار دارند، اما ابزار آنقدر سخت یا مزاحم است که کسی واقعاً از آن استفاده نمیکند. Semgrep سعی کرده این مانع را بردارد. هم سریع است، هم قابلفهم، هم قابلاتوماسیون، و هم برای توسعهدهنده آزاردهنده نیست. از طرف دیگر، برای تیم امنیت هم مناسب است، چون ruleها قابل نسخهسازی، قابل بازبینی و قابل گسترش هستند. این ترکیبِ سادگی و قدرت، دلیل اصلی محبوبیت آن در تیمهای DevSecOps است.
داشبورد Semgrep – تحلیل استاتیک کد SAST با Semgrep Code برای امنیت و کیفیت در DevSecOps👇
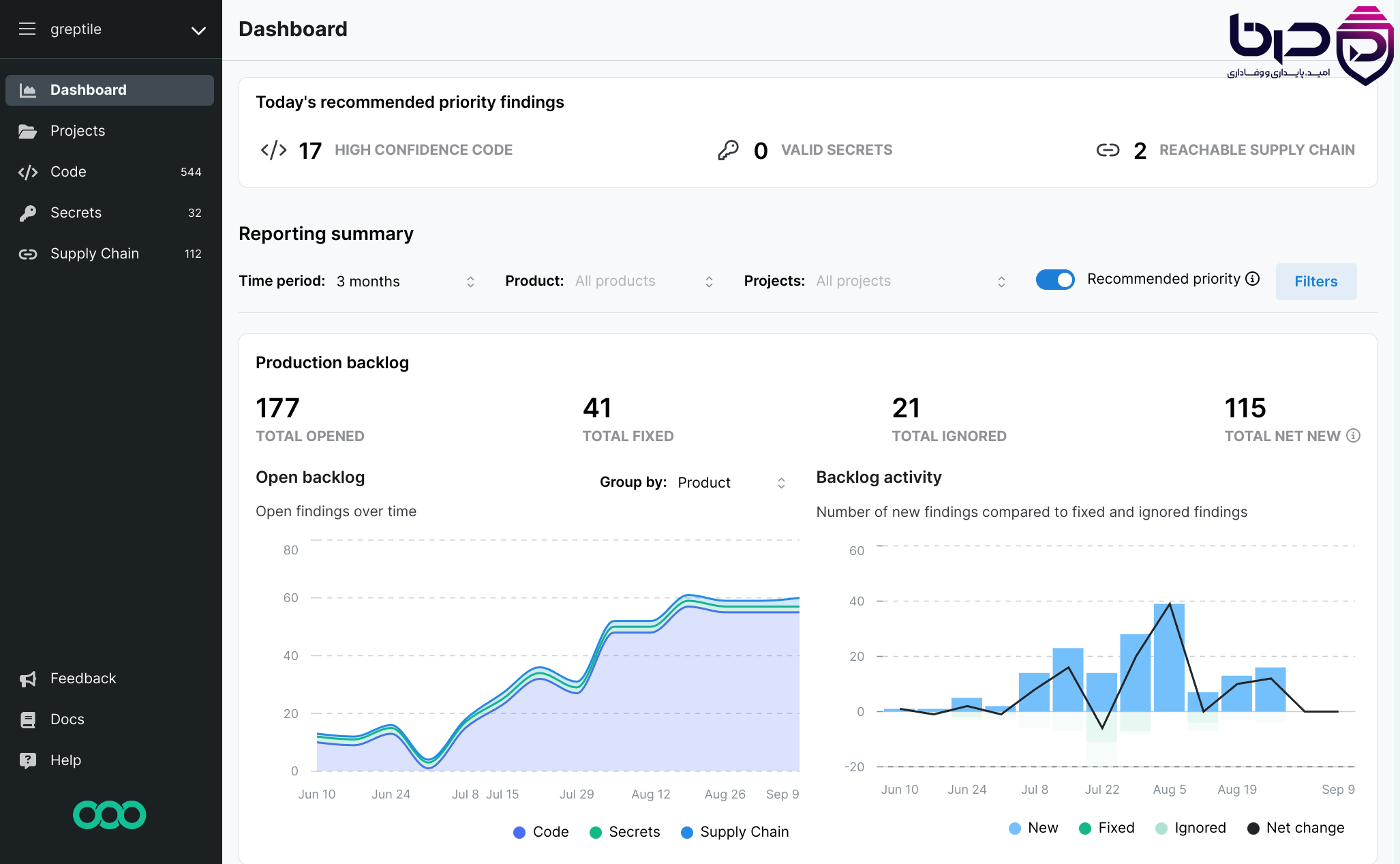
در این مقاله، Semgrep را از صفر تا سطح حرفهای بررسی میکنیم: اینکه دقیقاً چیست، چطور کار میکند، چطور نصب میشود، چطور rule مینویسیم، چطور آن را در CI/CD و IDE استفاده میکنیم، چطور با SCA و secrets کار میکند، چه تفاوتی بین CE و Platform وجود دارد، و در نهایت چطور میشود آن را به یک بخش واقعی از pipeline امنیتی پروژه تبدیل کرد. برای اینکه مقاله فقط «تعریف» نباشد، در هر بخش مثال عملی هم آورده شده تا متن هم آموزشی باشد و هم جذاب.
۱ Semgrep چیست؟
Semgrep یک ابزار تحلیل استاتیک کد است که برای پیدا کردن باگها، الگوهای ناامن، نقض استانداردهای کدنویسی، secrets لو رفته و برخی ضعفهای منطقی امنیتی به کار میرود. تفاوت اصلی Semgrep با بسیاری از ابزارهای سنتی این است که ruleهای آن شبیه خود کد نوشته میشوند و همین باعث میشود هم برای انسان قابلخواندن باشد و هم برای ماشین قابلتحلیل. مستندات رسمی Semgrep صریحاً میگویند که این پلتفرم SAST، SCA و secrets scanning را از یک نقطه مرکزی ارائه میکند.
فرض کن در یک پروژه Python کسی بهجای logging از `print` برای debug استفاده کرده است. از نظر امنیتی شاید این مورد همیشه بحرانی نباشد، اما از نظر کیفیت و maintenance مشکلساز است. Semgrep میتواند این الگو را تشخیص دهد و به تیم هشدار بدهد.
yaml
rules:
id: noprint
languages: python
message: "استفاده از print به جای logging توصیه نمیشود"
severity: WARNING
pattern: print...این rule ساده، نمونهی خوبی است از فلسفه Semgrep: rule باید آنقدر ساده باشد که تیم توسعه بتواند آن را بخواند و آنقدر قدرتمند که در پروژه واقعی ارزش داشته باشد.
۲ چرا Semgrep مهم است؟
ابزارهای SAST سنتی معمولاً سه مشکل دارند: کند هستند، false positive زیادی میدهند یا rule نوشتن در آنها سخت است. Semgrep سعی کرده این سه مشکل را همزمان حل کند. نسخه CE سبک است و برای اسکن محلی و یکباره مناسب است، در حالی که Semgrep Platform برای تیمهایی ساخته شده که به crossfile analysis، triage و remediation نیاز دارند.
Semgrep برای DevSecOps مهم است چون امنیت را نزدیک به لحظه توسعه میآورد. وقتی توسعهدهنده همانجا در IDE یا PR هشدار میگیرد، هزینهی اصلاح بسیار کمتر میشود. این مدل، کیفیت کد را بالا میبرد، سرعت تیم را کم نمیکند و جلوی ورود بخشی از خطاها را قبل از production میگیرد. Semgrep دقیقاً برای همین نوع workflow طراحی شده است.
اگر میخواهید بدانید DevSecOps دقیقاً چیست و چرا امنیت باید بخشی از فرآیند توسعه باشد، پیشنهاد میکنیم مقاله مرتبط را مطالعه کنید.
اگر یک تیم، هر PR را با Semgrep اسکن کند، احتمال اینکه یک hardcoded secret یا یک antipattern ساده قبل از merge کشف شود بسیار بیشتر است. بهجای اینکه بعداً در production یا audit به آن برسند، همان موقع جلوی ورودش گرفته میشود. همین تغییر کوچک در نقطهی کشف، در مقیاس یک تیم یا سازمان، بسیار بزرگ است.
۳ Semgrep چگونه کار میکند؟
Semgrep بر پایه rule و pattern matching کار میکند. ruleها در YAML نوشته میشوند و شامل بخشهایی مثل id، languages، message و severity هستند. مستندات رسمی تأکید میکنند که Semgrep فقط یک grep ساده نیست؛ بلکه از semantic analysis، constant propagation و در برخی موارد dataflow/taint analysis استفاده میکند. به همین دلیل، الگوهایی را تشخیص میدهد که در سطح syntactic ساده، بهراحتی دیده نمیشوند.
فرض کن در JavaScript یا Python یک مقدار حساس بهصورت hardcoded تعریف شده باشد. Semgrep میتواند آن را پیدا کند:
yaml
rules:
id: hardcodedpassword
languages: python, javascript
message: "رمز عبور hardcoded شناسایی شد"
severity: ERROR
pattern: |
$PASSWORD = "..."
اگرچه این rule ساده به نظر میرسد، اما در پروژه واقعی میتواند جلوی نشت credentialهای بسیار خطرناک را بگیرد. همینجا تفاوت Semgrep با regex مشخص میشود: در Semgrep، context کد مهم است، نه فقط متن خام.
۴ نصب و شروع سریع
شروع کار با Semgrep عمداً ساده طراحی شده است. در quickstart رسمی، پیشنیاز CLI داشتن Python 3.10 یا بالاتر است و Semgrep را میتوان از طریق روشهایی مثل نصب محلی یا استفاده در CI راهاندازی کرد. برای نخستین اسکن، خود مستندات Semgrep یک مسیر بسیار کوتاه و روشن پیشنهاد میکنند.
bash
semgrep scan config=auto .
```
این فرمان برای شروع عالی است، چون بدون اینکه rule خاصی بنویسی، میتوانی از configهای آماده استفاده کنی و خروجی اولیه بگیری. برای pipeline هم:
```bash
semgrep ciاستفاده میشود تا اسکن در جریان CI اجرا شود.
نصب و استفاده از Semgrep – نوشتن rule و اجرای اسکن محلی👇
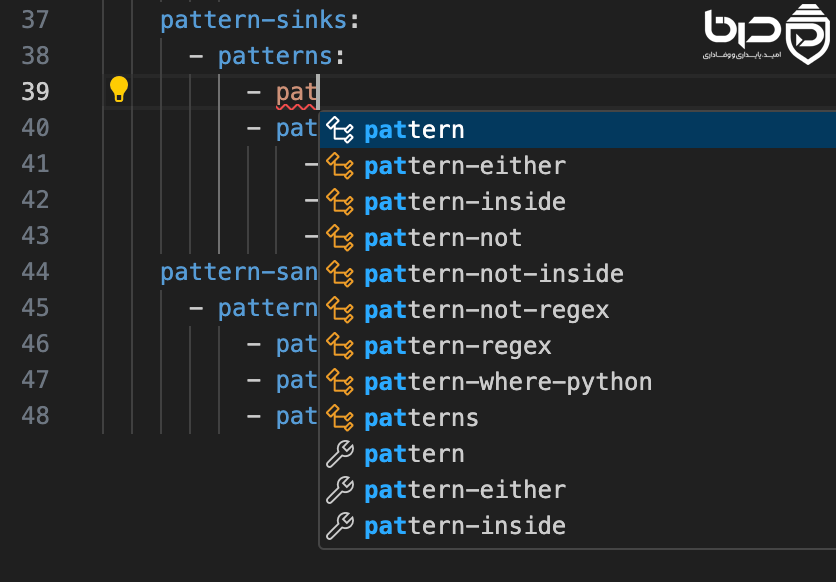
۵ نوشتن rule سفارشی
یکی از بخشهای جذاب Semgrep، rule نویسی است. ruleها YAML هستند، در Git قابل نگهداریاند و میتوانند برای code style، security policy یا antipatternها استفاده شوند. Semgrep rule syntax و glossary رسمی دارد که pattern syntax، semantic search، taint ruleها و fixها را توضیح میدهد. این باعث میشود rulewriting فقط برای تیم امنیت نباشد؛ توسعهدهنده هم بتواند در آن مشارکت کند.
جلوگیری از print در Python
yaml
rules:
id: noprint
languages: python
message: "استفاده از print به جای logging توصیه نمیشود"
severity: WARNING
pattern: print...
تشخیص SQL injection بالقوه
yaml
rules:
id: unsafesqlconcat
languages: python
message: "ساخت query بهصورت رشتهای خطر SQL injection دارد"
severity: ERROR
pattern: cursor.execute"..." + $X
این rule ساده است، اما برای آموزش تیم و جلوگیری از یک دسته اشتباه رایج فوقالعاده مفید است. در پروژههای واقعی، ruleهای taint دقیقتر از این هم نوشته میشوند.
نوشتن rule سفارشی در Semgrep – الگوهای شبیه کد برای تحلیل استاتیک👇
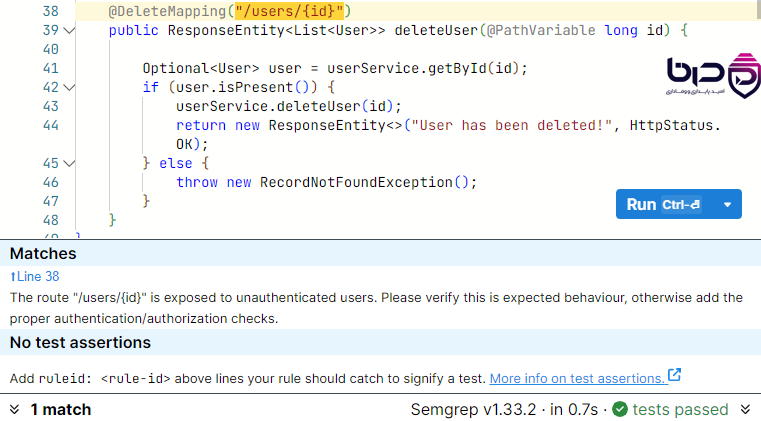
۶ Taint Analysis و مثالهای امنیتی واقعی
یکی از مهمترین قابلیتهای Semgrep در بخش rule نویسی، taint analysis است. در این مدل، میتوانی منبع دادهی ناامن source، محل خطرناک مصرف داده sink و مسیرهای بین آنها را تعریف کنی. این دقیقاً برای سناریوهایی مثل command injection، SQL injection، XSS و authorization mistakes بسیار مفید است. مستندات رسمی Semgrep هم crossfile و crossfunction analysis را برای نسخههای پیشرفتهتر توضیح میدهند.
فرض کن در یک برنامه، دادهی کاربر از request گرفته میشود و به `eval` میرسد. Semgrep میتواند این مسیر خطرناک را بهعنوان یک finding گزارش کند.
yaml
rules:
id: userinputtoeval
languages: python
message: "ورودی کاربر نباید مستقیم به eval برسد"
severity: ERROR
mode: taint
patternsources:
pattern: request.get_json...
patternsinks:
pattern: eval...این نوع ruleها برای کشف یک رفتار واقعی خطرناک بسیار ارزشمندند، چون فقط دنبال یک عبارت خاص نمیگردند؛ مسیر انتقال داده را هم بررسی میکنند.
۷ Semgrep Code و تحلیل عمیقتر
Semgrep Code نسخهای است که برای codebaseهای جدیتر و پیچیدهتر ساخته شده است. تفاوت اصلی آن با CE در همینجاست: CE perfile است، اما Semgrep Code crossfunction و crossfile analysis را ارائه میدهد. این یعنی Semgrep Code میتواند context بیشتری ببیند و در نتیجه true positiveهای بهتری بدهد.
مثال عملی :فرض کن یک تابع داده را sanitize میکند، اما تابع دیگر در فایل دیگری آن را مصرف میکند. در CE ممکن است این رابطه بهطور کامل دیده نشود، اما در Semgrep Code، crossfile analysis میتواند این مسیر را دنبال کند و نتیجه دقیقتری بدهد. این موضوع مخصوصاً در monorepoها و پروژههای چندلایه مهم است.
Semgrep در release notes رسمی ۲۰۲۶ اعلام کرده که AIpowered detection برای پیدا کردن باگهای پیچیده مثل IDOR و broken authorization بهصورت beta اضافه شده است. این قابلیت اهمیت زیادی دارد، چون این دسته از باگها معمولاً با ruleهای ساده pattern matching پیدا نمیشوند و به تحلیل semantic بیشتری نیاز دارند.
۸ Semgrep Supply Chain و Secrets Detection
Semgrep فقط کد خودت را نمیبیند؛ وابستگیها و secrets را هم بررسی میکند. Semgrep Supply Chain برای تحلیل dependencyها، شناسایی آسیبپذیریهای قابلدسترسی و تولید SBOM طراحی شده است. مستندات رسمی توضیح میدهند که reachability analysis در این بخش کمک میکند فقط vulnerabilityهایی flag شوند که واقعاً به کد شما میرسند و قابل بهرهبرداریاند.
مثال عملی :فرض کن پروژهای از یک کتابخانه آسیبپذیر استفاده میکند، اما آن کد خطرناک هیچوقت در مسیر اجرا قرار نمیگیرد. Semgrep Supply Chain با reachability analysis تلاش میکند این موارد را از آسیبپذیریهایی که واقعاً قابل بهرهبرداریاند جدا کند. نتیجه این است که تیم امنیت، وقتش را روی یافتههای مهمتر میگذارد.
Semgrep Secrets هم برای پیدا کردن credential، token، password و API key لو رفته است. مستندات رسمی و blogهای معرفی این محصول توضیح میدهند که این سیستم فقط از الگوهای سطحی استفاده نمیکند، بلکه از semantic analysis و validation هم بهره میگیرد تا false positive کمتر شود.
اگر کسی اشتباهاً این را در repository commit کند:
python
API_KEY = "sk_live_123456789"Semgrep Secrets میتواند چنین موردی را تشخیص دهد و جلوی انتشار آن را بگیرد. در تیمهای واقعی، همین یک کشف ممکن است از یک incident بزرگ جلوگیری کند.
Semgrep Secrets Scanning – تشخیص و جلوگیری از نشت کلیدهای محرمانه و credentials👇
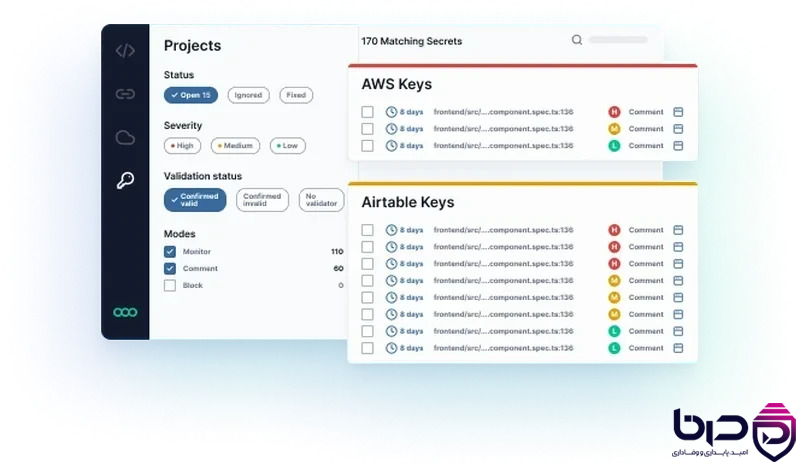
۹ Semgrep در CI/CD و PR Workflow
Semgrep برای ادغام در CI/CD ساخته شده است. مستندات deployment نشان میدهند که برای GitHub Actions، GitLab CI/CD، Jenkins، Bitbucket، CircleCI، Buildkite، Azure Pipelines و سایر runnerها راهنمای رسمی دارد. این یعنی میتوانی Semgrep را بهعنوان یک security gate واقعی در pipeline قرار بدهی.
مثال عملی GitLab CI
yaml
semgrep:
image: semgrep/semgrep
script:
semgrep ci config=autoاین سناریو خیلی ارزشمند است، چون به محض ایجاد یک merge request، اسکن امنیتی انجام میشود و اگر rule مهمی نقض شده باشد، همانجا visible میشود. این مدل، هم سرعت توسعه را حفظ میکند و هم جلوی ورود کد ناامن را میگیرد.
در GitHub Actions هم میتوان Semgrep را به عنوان بخشی از workflow اضافه کرد تا قبل از merge، اسکن خودکار انجام شود. این یکی از رایجترین روشهای استفاده از Semgrep در تیمهای مدرن است.
اگر میخواهید دقیقتر با فرآیند CI/CD و نقش آن در اتوماسیون توسعه آشنا شوید، حتماً مقاله «CI/CD چیست» را بخوانید، چون Semgrep معمولاً در همین مرحله استفاده میشود.
ادغام Semgrep در CI/CD Pipeline – اسکن خودکار کد در GitLab CI و GitHub Actions👇
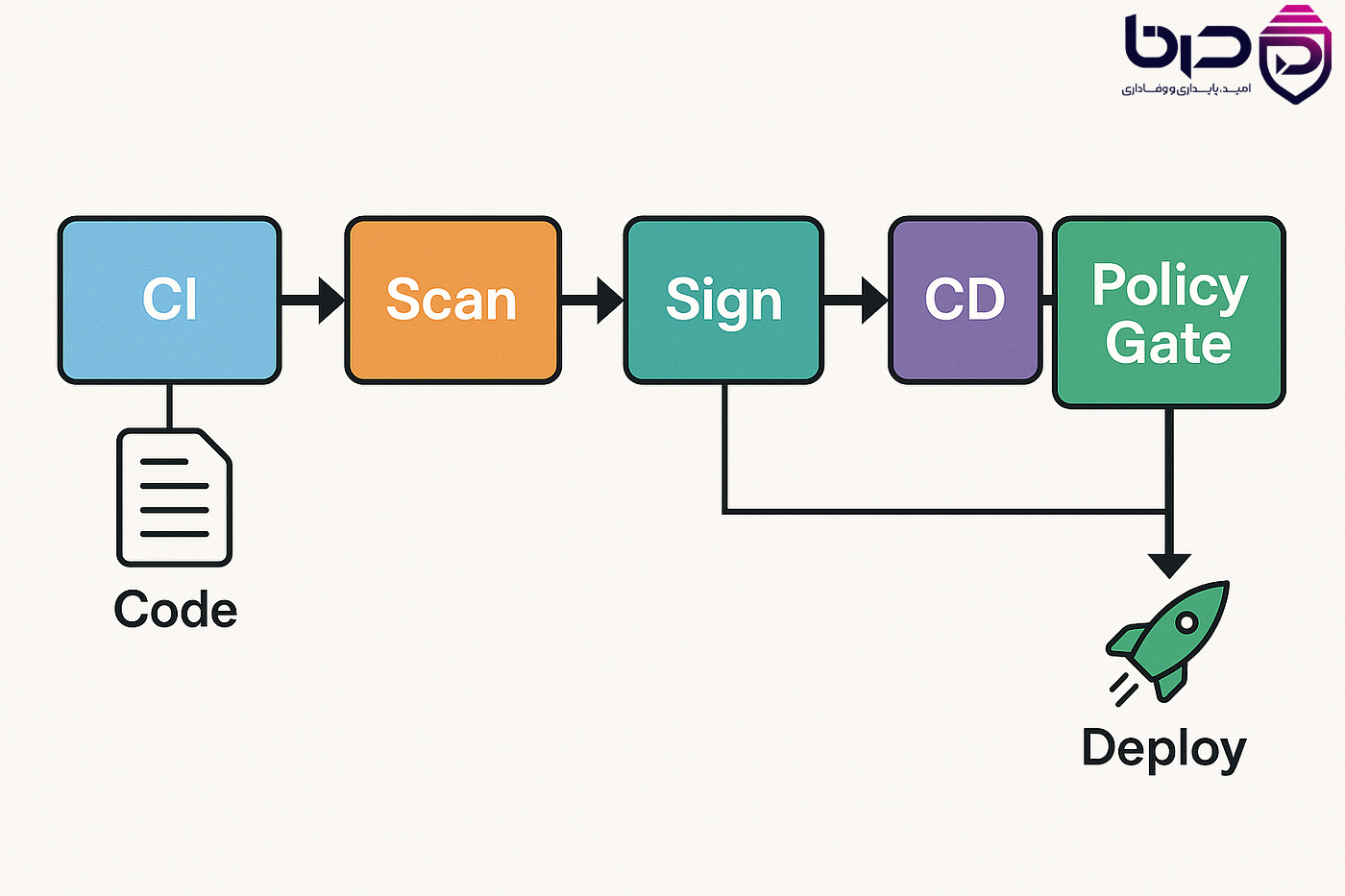
۱۰ Semgrep در IDE و دنیای AI coding
Semgrep فقط برای CI نیست؛ به دنیای IDE و ابزارهای AI هم وارد شده است. مستندات MCP نشان میدهند که Semgrep Plugin با Claude Code، Cursor، Windsurf و Codex سازگار است و بهعنوان MCP client یا plugin کار میکند. این یعنی Semgrep میتواند در جریان تولید کد توسط agentها هم حضور داشته باشد.
فرض کن یک توسعهدهنده با Cursor یا Claude Code در حال ساخت یک endpoint است. اگر agent کدی تولید کند که شامل الگوی ناامن باشد، Semgrep plugin میتواند همانجا هشدار بدهد یا حتی مسیر اصلاح را پیشنهاد کند. این دقیقاً همان چیزی است که Semgrep از آن بهعنوان secure vibe coding یاد میکند.
۱۱ Autofix و remediation
Semgrep Autofix یکی از جذابترین قابلیتهای نسخه جدید است. در release notes رسمی ۲۰۲۶ آمده که Autofix برای Semgrep Code به beta رسیده و برای findingهای Code هم draft pull request میسازد. این قابلیت زمان فاصله بین «کشف مشکل» و «رفع مشکل» را کم میکند.
اگر Semgrep تشخیص دهد که query بهصورت unsafe ساخته شده، Autofix میتواند یک تغییر پیشنهادی ایجاد کند تا developer سریعتر آن را بازبینی و merge کند. این یعنی ابزار فقط هشدار نمیدهد؛ در مسیر remediation هم کمک میکند. semgrep.dev10
۱۲ Semgrep CE یا Platform؟
Semgrep CE نسخه متنباز، سبک و سریع است و برای اسکنهای یکباره، استفاده محلی و تیمهایی که میخواهند شروع کمهزینه داشته باشند، بسیار مناسب است. مستندات رسمی میگویند CE برای افرادی مثل security auditorها، pentesterها و کسانی که اسکنهای adhoc دارند، گزینه خوبی است.
Semgrep Platform و Semgrep Code برای تیمهایی مناسباند که به تحلیل عمیقتر، مدیریت findings، crossfile analysis، SCA و secrets بهصورت یکپارچه نیاز دارند. در واقع انتخاب بین CE و Platform فقط انتخاب بین «رایگان» و «پولی» نیست؛ انتخاب بین «اسکن ساده» و «پلتفرم امنیتی کامل» است.
۱۳ بهترین شیوههای استفاده
بهترین راه استفاده از Semgrep این است که آن را در سه سطح بهکار ببری:
- روی لپتاپ توسعهدهنده
- روی PR/MR
- داخل CI/CD
این روش باعث میشود امنیت بهجای اینکه یک مرحلهی انتهایی باشد، بخشی طبیعی از workflow شود.
مثال عملی :توسعهدهنده قبل از commit، local scan میزند.
هنگام PR، pipeline اجرا میشود.
اگر finding مهمی باشد، merge block میشود.
اگر finding قابل اصلاح باشد، Autofix یا rule fix پیشنهاد میدهد.
این چرخه باعث میشود هم سرعت تیم حفظ شود و هم امنیت بهصورت سیستماتیک بالا برود.
Semgrep در DevSecOps – از اسکن محلی تا پلتفرم کامل امنیتی کد در سرور ابری👇
سوالات متداول & FAQ Schema
Semgrep چیست و چه تفاوتی با ابزارهای سنتی SAST دارد؟
Semgrep یک ابزار تحلیل استاتیک کد است که با استفاده از الگوهای شبیه کد (نه regexهای پیچیده یا AST سنگین)، باگها و آسیبپذیریها را شناسایی میکند. برخلاف ابزارهای سنتی SAST که معمولاً کند و پیچیده هستند، Semgrep سریعتر، سبکتر و برای توسعهدهندگان قابلفهمتر است.
آیا Semgrep فقط برای امنیت استفاده میشود؟
خیر، Semgrep علاوه بر امنیت، برای بهبود کیفیت کد، enforce کردن coding standardها و جلوگیری از anti-patternها هم استفاده میشود. در واقع میتوان از آن بهعنوان یک quality gate در pipeline استفاده کرد.
تفاوت Semgrep Community Edition و Semgrep Code چیست؟
نسخه Community Edition رایگان و متنباز است و بیشتر برای اسکنهای ساده و محلی استفاده میشود. در مقابل، Semgrep Code قابلیتهای پیشرفتهتری مثل تحلیل cross-file، تشخیص دقیقتر آسیبپذیریها و ویژگیهای AI-based را ارائه میدهد.
آیا Semgrep برای پروژههای کوچک هم مناسب است؟
بله، حتی پروژههای کوچک هم میتوانند از Semgrep بهره ببرند. در واقع، استفاده زودهنگام از این ابزار باعث میشود از همان ابتدا استانداردهای امنیتی در پروژه رعایت شوند و در آینده هزینههای اصلاح کاهش یابد.
آیا استفاده از Semgrep باعث کند شدن CI/CD میشود؟
اگر بهدرستی پیادهسازی شود، خیر. Semgrep بسیار سریع است و میتوان اسکنها را بهصورت مرحلهای در pipeline توزیع کرد تا هم امنیت حفظ شود و هم سرعت توسعه کاهش پیدا نکند.
آیا میتوان Semgrep را با Docker و Kubernetes استفاده کرد؟
بله، Semgrep بهراحتی در محیطهای کانتینری اجرا میشود و میتوان آن را در pipelineهای مبتنی بر Docker و Kubernetes ادغام کرد. این موضوع برای تیمهایی که روی سرورهای ابری کار میکنند بسیار مهم است.
Semgrep چگونه secrets را شناسایی میکند؟
Semgrep با استفاده از ترکیبی از pattern matching، entropy analysis و validation تلاش میکند secrets واقعی را تشخیص دهد و از false positive جلوگیری کند.
چرا اسکن dependencyها (Supply Chain) اهمیت دارد؟
زیرا بسیاری از حملات از طریق کتابخانههای شخص ثالث انجام میشوند. یک dependency آسیبپذیر میتواند بدون اطلاع شما وارد پروژه شود و ریسک جدی ایجاد کند. Semgrep با reachability analysis کمک میکند فقط موارد واقعاً خطرناک شناسایی شوند.
آیا Semgrep جایگزین Code Review میشود؟
خیر، Semgrep مکمل Code Review است. این ابزار کارهای تکراری و قابل اتوماسیون را انجام میدهد تا تیم توسعه بتواند روی منطق و طراحی تمرکز کند.
آیا Semgrep در دنیای AI coding هم کاربرد دارد؟
بله، Semgrep با ابزارهایی مانند Cursor و Claude Code ادغام شده و میتواند در همان لحظه تولید کد توسط AI، مشکلات امنیتی را شناسایی کند.
نتیجهگیری & Call To Action
- در دنیای امروز، نوشتن کد بدون در نظر گرفتن امنیت، مثل ساختن یک ساختمان بدون فونداسیون است. شاید در ابتدا همهچیز خوب بهنظر برسد، اما دیر یا زود، یک مشکل کوچک میتواند به یک بحران بزرگ تبدیل شود.
- Semgrep دقیقاً برای جلوگیری از همین سناریو ساخته شده است.
- این ابزار به شما کمک میکند امنیت را از یک فرآیند دیرهنگام و واکنشی، به یک بخش طبیعی و همیشگی از توسعه تبدیل کنید. با استفاده از Semgrep، میتوانید قبل از اینکه کد به production برسد، مشکلات را شناسایی کنید، هزینههای اصلاح را کاهش دهید و کیفیت کلی پروژه را بهطور محسوسی افزایش دهید.
- تیمهایی که از Semgrep استفاده میکنند، فقط امنیت بیشتری ندارند؛ بلکه سریعتر توسعه میدهند، خطاهای کمتری دارند و pipelineهای پایدارتر و حرفهایتری میسازند. آنها بهجای اینکه منتظر وقوع مشکل باشند، آن را از ابتدا متوقف میکنند.
- اما یک نکته مهم وجود دارد:
- Semgrep بهتنهایی کافی نیست.
- برای اینکه بهترین نتیجه را بگیرید، باید آن را در یک زیرساخت مناسب اجرا کنید. اجرای اسکنهای مداوم، pipelineهای CI/CD، پروژههای کانتینری و تحلیل dependencyها نیاز به سرورهای پایدار، سریع و امن دارد. اگر زیرساخت شما ضعیف باشد، حتی بهترین ابزارها هم نمیتوانند عملکرد واقعی خود را نشان دهند.
اگر میخواهی از رقبا جلو بزنی، باید همین امروز شروع کنی😁
امنیت را به pipeline خود اضافه کن، کدهایت را هوشمندانه بررسی کن و Semgrep را به بخشی از DNA تیم توسعهات تبدیل کن.