در دنیای امنیت نرمافزار، چالش اصلی معمولاً «نبود ابزار» نیست؛ چالش واقعی این است که ابزارهای مختلف، دادههای بسیار زیاد، تکراری و گاهی متناقض تولید میکنند. یک تیم امنیتی ممکن است همزمان از SAST، DAST، SCA، Container Scanning، IaC Scanning، Pentest Report و حتی Manual Review استفاده کند. هرکدام از این ابزارها حقیقتی از سطح حمله را نشان میدهند، اما مشکل اینجاست که این حقیقتها در قالبهای متفاوت، با شدتهای مختلف و اغلب بدون context واحد گزارش میشوند.
DefectDojo دقیقاً برای حل همین مسئله طراحی شده است: یک پلتفرم متنباز برای vulnerability management، DevSecOps و ASPM که میتواند نتایج ابزارهای گوناگون را دریافت کند، نرمالسازی نماید، موارد تکراری را حذف یا همارزسازی کند، و آنها را در قالب یک جریان عملیاتی قابلمدیریت برای remediation، reporting، SLA tracking و issue tracking ارائه دهد. در واقع، DefectDojo فقط یک dashboard نیست؛ یک مرکز فرماندهی امنیت است.
اگر هنوز با فلسفه DevSecOps آشنا نیستید، پیشنهاد میکنیم ابتدا مقاله «DevSecOps چیست؟ تزریق امنیت به CI/CD و زیرساختهای ابری» را مطالعه کنید تا بهتر متوجه شوید DefectDojo در چه نقطهای از چرخه امنیت قرار میگیرد.
در نسخه OpenSource، این پلتفرم برای تیمهایی که میخواهند با هزینه کم اما با ساختار حرفهای شروع کنند، امکاناتی مثل import/reimport برای بیش از 200 ابزار امنیتی، REST API، deduplication، Jira integration و مدل داده منظم را فراهم میکند. در سوی دیگر، نسخه Pro امکانات پیشرفتهتری مانند metrics بهتر، priority/risk triage، rules engine، advanced deduplication و connectorهای بیشتر ارائه میدهد. نتیجه این است که DefectDojo هم برای یک تیم کوچک AppSec مناسب است و هم برای یک سازمان بزرگ با چندین pipeline، چندین محصول و چندین تیم توسعه.
اگر بخواهیم خیلی روشن بگوییم، DefectDojo همان نقطهای است که خروجیهای Semgrep، ZAP، Burp، Trivy، SCA Scannerها، Pentest Reportها و حتی یافتههای دستی را از وضعیت «فایلهای جداگانه و پراکنده» به وضعیت «یک سیستم مدیریتی منسجم و قابلردیابی» منتقل میکند. این یعنی امنیت از حالت reactive و پراکنده، به یک فرآیند measurable، traceable و قابلتصمیمگیری تبدیل میشود.
۱. بحران ابزارهای امنیتی جزیرهایز
در معماریهای مدرن، بهویژه در تیمهایی که با CI/CD، میکروسرویسها، کانتینرها و releaseهای مداوم سروکار دارند، امنیت دیگر یک فعالیت تکمرحلهای نیست. یک ابزار SAST ممکن است در کد منبع خطا پیدا کند، یک اسکنر SCA همان خطا را در dependencyها نشان دهد، یک DAST آن را در runtime ببیند، و یک تیم pentest هم همان باگ را به شکل دستی گزارش کند. اگر این دادهها در یک سیستم متمرکز جمع نشوند، تیم امنیت با حجم زیادی از هشدارهای تکراری، false positiveها، تناقضها و گزارشهای غیرقابلاقدام مواجه میشود.
DefectDojo دقیقاً برای رفع همین پراکندگی ساخته شده و میتواند گزارشهای صدها ابزار تجاری و متنباز را وارد کند، آنها را به یک مدل یکنواخت تبدیل کند و از داخل آن یک تصویر واحد از وضعیت امنیتی سازمان بسازد. این یکپارچهسازی فقط برای زیبایی داشبورد نیست؛ هدف اصلی آن کاهش noise و افزایش کیفیت تصمیمگیری است.
در عمل، وقتی یک vulnerability از سه مسیر مختلف گزارش میشود، تیم نمیخواهد سه ticket جداگانه، سه چرخه triage و سه پیگیری مجزا داشته باشد. تیم به یک finding واحد نیاز دارد که همه شواهد، همه منبعها و همه وضعیتها را در خودش جمع کند. DefectDojo این مسئله را با ساختار داخلی خود، deduplication، و contextسازی روی محصول و test حل میکند.
مثال عملی:
فرض کن Semgrep در یک کنترلر ASP.NET MVC یک مشکل XSS پیدا میکند. همان روز Burp در مسیر HTTP همان endpoint را report میکند و یک pentest manual هم همان مشکل را تأیید میکند. اگر این دادهها در سه ابزار جدا باقی بمانند، تیم توسعه سهبار درگیر میشود. اما اگر همه آنها داخل DefectDojo وارد شوند، به یک picture واحد میرسیم: یک vulnerability اصلی با چندین observation. این دقیقاً همان چیزی است که vulnerability fatigue را کاهش میدهد.
داشبورد و Hero Image👇
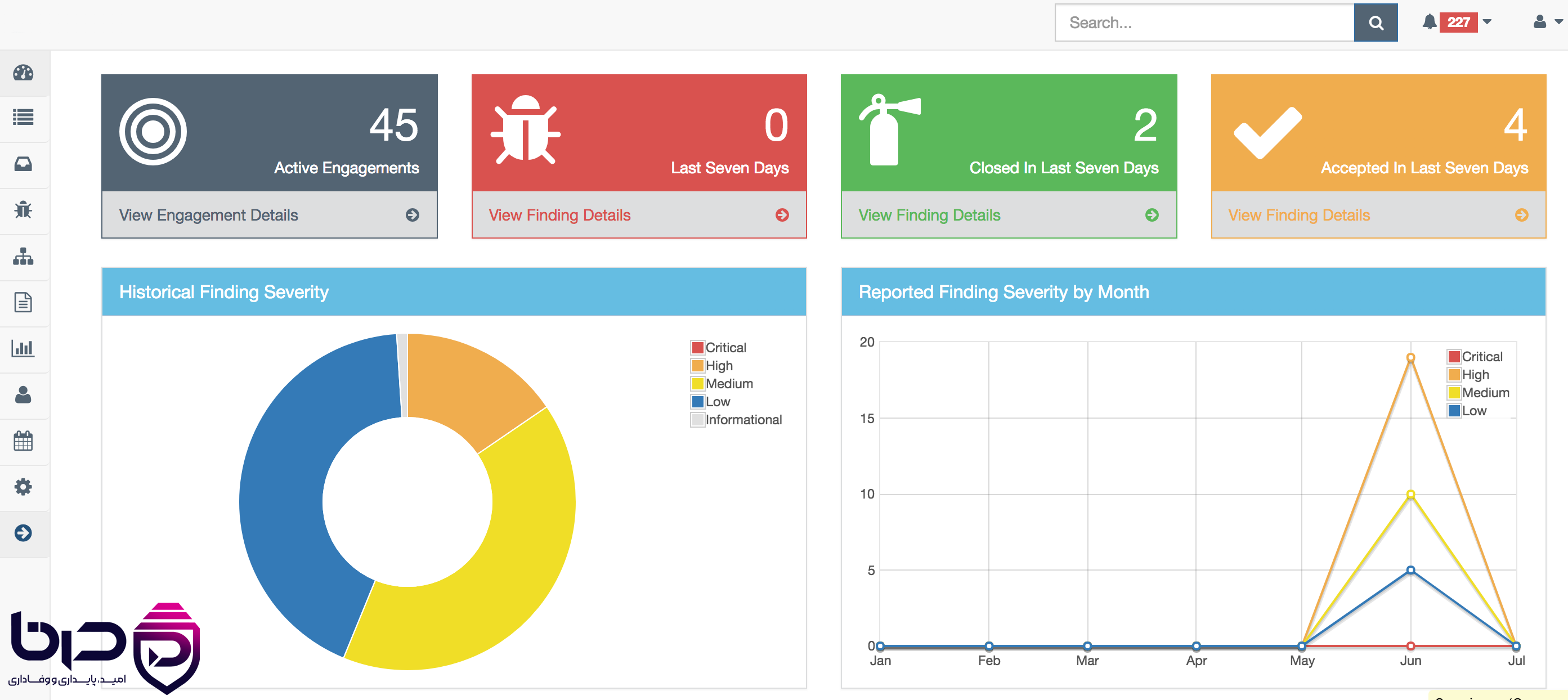
۲. کالبدشکافی مدل دادهای DefectDojo
قدرت واقعی DefectDojo در UI آن نیست؛ در مدل دادهای ساختیافته آن است. این پلتفرم امنیت را نه بهعنوان یک collection از گزارشها، بلکه بهعنوان یک hierarchy عملیاتی سازماندهی میکند. هسته این مدل از چند لایه اصلی تشکیل شده است: Product Type، Product، Engagement، Test و Finding؛ و در سطح جزئیتر، Endpointها نیز برای ثبت محل وقوع آسیبپذیری استفاده میشوند.
Product Type
Product Type معمولاً سطحی است برای دستهبندی کسبوکاری یا سازمانی. مثلاً میتوانی محصولاتی را که متعلق به یک دپارتمان، یک domain تجاری یا یک تیم توسعه خاص هستند زیر یک Product Type قرار دهی. این سطح برای مدیریت permissionها، grouping و سیاستهای امنیتی بسیار مهم است. اگر سازمان بزرگ باشد، این لایه میتواند مرز بین چند تیم یا چند خط محصول را مشخص کند.
Product
Product در واقع همان سرویس، برنامه، اپلیکیشن یا پروژهای است که امنیت آن را میخواهی مدیریت کنی. برای مثال، `Web App`, `Mobile App`, `Auth Service`, `Payment Gateway` یا `Admin Panel` همگی میتوانند Product باشند. هر Product میتواند چندین Engagement، چندین Test و تعداد زیادی Finding داشته باشد. این لایه برای mapping امنیت به دارایی واقعی سازمان حیاتی است.
Engagement
Engagement یک بازه کاری، کمپین تست یا چرخه ارزیابی امنیتی است. مثلاً میتوانی برای هر release cycle، هر quarter، هر pentest campaign یا هر برنامه remediation یک Engagement جدا تعریف کنی. Engagement کمک میکند یافتهها در context زمانی و پروژهای درست قرار بگیرند. این یعنی فرق بین یک finding در «Q1 Release 2026» و همان finding در «PostLaunch Hardening» کاملاً مشخص میشود.
Test
Test ظرفی است که نتایج یک اسکن یا یک ارزیابی را در خود نگه میدارد. هر Test معمولاً به یک ابزار، یک اجرا یا یک snapshot خاص از وضعیت امنیتی مربوط است. مثلاً یک Test میتواند خروجی Semgrep، دیگری خروجی ZAP و سومی خروجی Trivy باشد. مزیت این لایه این است که تاریخچه ابزار، زمان اجرا، نوع scan و context مربوطه حفظ میشود.
Finding
Finding کوچکترین واحد عملیاتی در DefectDojo است؛ یعنی همان vulnerability، issue، misconfiguration یا weakness که باید بررسی شود. هر Finding میتواند severity، description، evidence، file path، line number، endpoints، CWE، CVE، tags و وضعیت remediation داشته باشد. در عمل، همه چیز حول Finding میچرخد: triage، deduplication، push به Jira، status update و reporting. )
Endpoint
Endpoint برای ثبت نقطه دقیق وقوع vulnerability استفاده میشود. مثلاً URL، route، API path، IP، domain، port یا حتی یک مسیر خاص در اپلیکیشن میتواند Endpoint باشد. این سطح جزئینگری باعث میشود security team فقط بداند «مشکلی وجود دارد» نباشد، بلکه دقیقاً بداند «کجا»، «در چه مسیر»، و «در چه سطحی» مسئله رخ داده است.
مثال عملی:
فرض کن سه محصول داری: `Web App`, `Mobile App` و `Auth Service`. برای هرکدام یک Product Type تعریف میکنی. سپس برای هر release یا فصل، یک Engagement مثل `Q2 2026 Security Scan` میسازی. داخل آن چند Test ایجاد میکنی: Semgrep، ZAP و Dependency Scan. حالا هر Finding دقیقاً میگوید که مشکل در کدام محصول، در کدام اسکن، در کدام مسیر و با کدام منبع کشف شده است. این سطح از context چیزی نیست که از فایل خام CSV یا PDF بهراحتی بهدست بیاید.
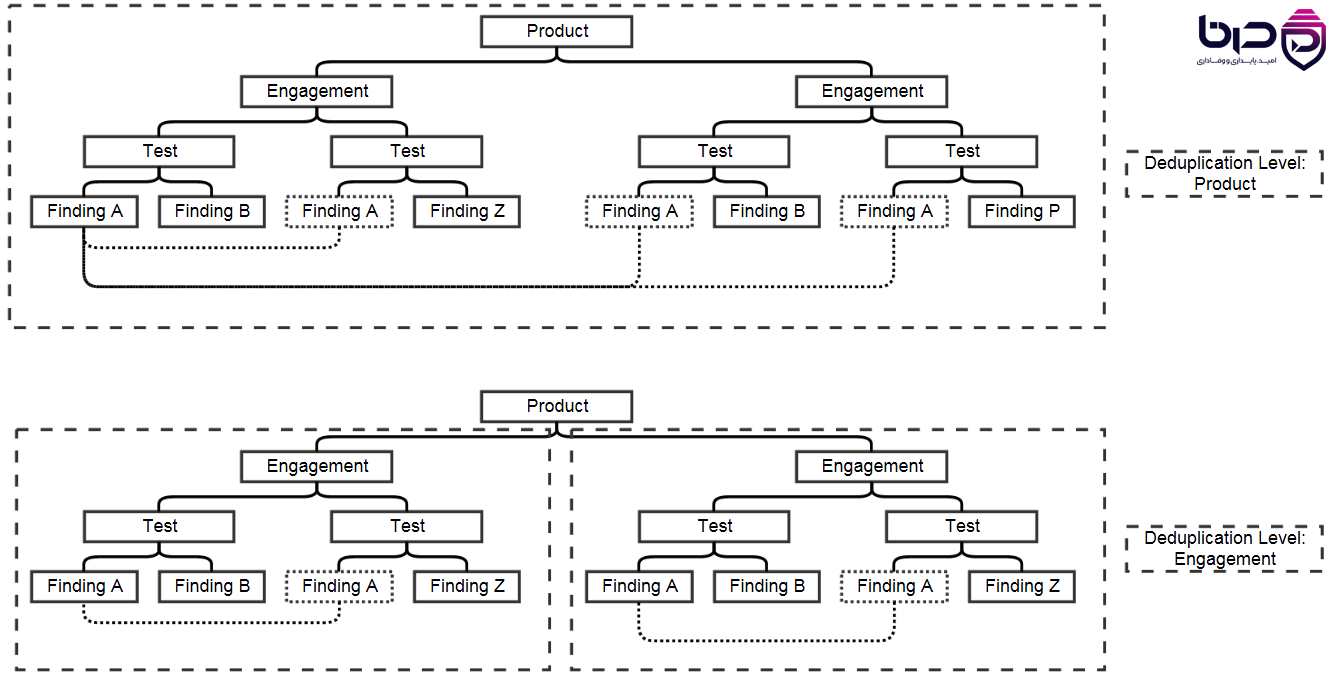
۳. Deduplication؛ جادوی حذف هوشمند تکراریها
یکی از مهمترین مشکلات در امنیت نرمافزار، duplicate finding است. یک باگ واحد ممکن است در چند اسکن، با چند ابزار و با چند فرمت مختلف گزارش شود. اگر سیستم مدیریت آسیبپذیری نتواند این موارد را بهدرستی تشخیص دهد، تیم امنیت در دریایی از تکرار غرق میشود. DefectDojo دقیقاً برای ingest کردن گزارشهای bulk طراحی شده و deduplication را بهعنوان یک قابلیت مرکزی در نظر گرفته است، نه یک feature جانبی.
منطق deduplication چگونه عمل میکند؟
وقتی چند Test در یک Product یک آسیبپذیری مشابه را نشان دهند، DefectDojo میتواند آنها را بهعنوان duplicate تشخیص دهد. در این حالت، معمولاً یک Finding بهعنوان اصلی باقی میماند و موارد بعدی بهعنوان duplicate ثبت میشوند تا تیم فقط یک نقطه اقدام داشته باشد. این کار باعث میشود remediation workflow سادهتر، دقیقتر و قابلپیگیریتر شود.
Deduplication بر اساس چه چیزهایی انجام میشود؟
در نسخه OpenSource، deduplication از طریق تنظیمات و environment variableها قابلتنظیم است. الگوریتمهایی مانند `unique_id_from_tool`، `hash_code` یا ترکیب آنها میتوانند تعیین کنند که یک finding چقدر شبیه finding قبلی است. فیلدهایی مانند `title`, `severity`, `cwe`, `vulnerability_ids`, `file_path`, `line` و حتی endpoint میتوانند در hash وارد یا از آن حذف شوند. این انعطاف برای ابزارهای مختلف بسیار مهم است، چون همه اسکنرها یکسان رفتار نمیکنند.
Crosstool deduplication
یکی از ارزشمندترین بخشها این است که بتوانی findingهای تولیدشده توسط ابزارهای متفاوت را هم بهصورت هوشمند به هم ربط بدهی. برای مثال، Trivy یک dependency آسیبپذیر را در image گزارش میکند، Semgrep همان weakness را در کد تشخیص میدهد و ZAP نیز اثر آن را در runtime میبیند. اگر deduplication خوب تنظیم شده باشد، این سه سیگنال به یک مسئله واحد تبدیل میشوند. در Pro edition، تنظیمات پیشرفتهتری مانند `Hash Code` و `Global Component` برای سناریوهای SCA نیز در دسترساند.
مثال عملی:
یک dependency قدیمی در `pom.xml` باعث میشود یک آسیبپذیری در لایه Java Backend وجود داشته باشد. Semgrep آن را در source code منعکس میکند، Trivy آن را در container image میبیند، و یک SCA scanner هم نسخه آسیبپذیر package را گزارش میدهد. اگر اینها مستقل بمانند، تیم سه issue خواهد داشت. اما اگر deduplication درست تنظیم شود، DefectDojo آنها را در یک finding اصلی جمع میکند و فقط شواهد را از چند منبع نگه میدارد.
.png)
۴. Import و Reimport؛ قلب جریان داده در DefectDojo
در DefectDojo، ورود داده فقط «آپلود یک فایل» نیست؛ بلکه بخشی از یک lifecycle دقیق است. دو مفهوم بسیار مهم در این سیستم Import و Reimport هستند.
Import
Import زمانی استفاده میشود که یک گزارش امنیتی را برای اولینبار وارد میکنی. این گزارش بهعنوان snapshot از وضعیت امنیتی در یک نقطه زمانی خاص ذخیره میشود. Import برای شروع کار، ورود نتایج اولیه یا ingestion از ابزار جدید بسیار مهم است.
Reimport
Reimport زمانی بهکار میرود که همان scan بهصورت دورهای یا در pipeline تکرار میشود و تو میخواهی همان Test قبلی را با نتایج جدید بهروزرسانی کنی. در این حالت، DefectDojo findingهای جدید، رفعشده، باقیمانده و duplicate را نسبت به داده قبلی مقایسه میکند. این ویژگی برای tracking تغییرات واقعی بسیار ارزشمند است، چون بهجای ساختن تاریخچههای جداگانه و گاهی آشفته، یک history منظم و قابلتحلیل تولید میشود.
API v2 و اتوماسیون
در API v2، import و reimport از طریق endpointهای `importscan` و `reimportscan` انجام میشوند. اگر `auto_create_context` فعال باشد، DefectDojo میتواند Product Type، Product، Engagement و حتی Test را خودکار ایجاد کند. این قابلیت برای CI/CD بسیار حیاتی است، چون دیگر لازم نیست همه چیز را دستی در UI بسازی. خود pipeline میتواند context را ایجاد و نتایج را وارد کند.
بهترین الگو برای pipelineها
مستندات توصیه میکنند که هر repository یا pipeline یک Engagement مشخص داشته باشد و هر اجرای تکراری به همان Test مرتبط شود. در این الگو، بهجای ساخت Test جدید در هر بار اجرا، از Reimport استفاده میشود تا history تمیز بماند و نویز کمتر شود. این کار مخصوصاً برای trend analysis، vulnerability aging و اندازهگیری MTTR بسیار مفید است.
مثال عملی:
در یک GitLab pipeline، Semgrep و یک SCA scanner هر شب اجرا میشوند. شب اول، نتایج Import میشوند. شبهای بعدی، همان Testها Reimport میشوند. نتیجه این است که DefectDojo دقیقاً نشان میدهد چه finding جدیدی اضافه شده، کدام مورد رفع شده و کدام مورد هنوز باز است. این مدل برای تیمهایی که release مداوم دارند، یک نعمت واقعی است.
۵. ادغام با Jira و سیستمهای Issue Tracking
امنیت زمانی مؤثر میشود که به فرآیند توسعه وصل شود. اگر vulnerability فقط در یک dashboard امنیتی بماند و به کار توسعه نرسد، ارزش عملی آن محدود میشود. DefectDojo برای همین سناریو، integration با Jira و دیگر ابزارهای issue tracking را ارائه میدهد.
Jira sync
DefectDojo میتواند Findingها را به Jira push کند و از طریق webhook یا sync معکوس، وضعیت issueها را دوباره به DefectDojo برگرداند. این یعنی امنیت و توسعه از هم جدا نیستند؛ بلکه در یک گردش کار مشترک حرکت میکنند.
Bidirectional workflow
در یک workflow دوطرفه، finding در DefectDojo ایجاد میشود، یک Jira issue برای آن ساخته میشود، تیم توسعه آن را در sprint قرار میدهد، سپس پس از اصلاح، status در Jira تغییر میکند و این تغییر در DefectDojo هم دیده میشود. چنین مدلی باعث میشود امنیت از حالت «فهرست هشدارها» به «فرآیند اجرایی» تبدیل شود.
پشتیبانی از چند پلتفرم
در نسخه Pro، علاوه بر Jira، اتصال به Azure DevOps، GitHub، GitLab Boards و ServiceNow هم پشتیبانی میشود. این موضوع مهم است، چون همه سازمانها از Jira استفاده نمیکنند و بعضی تیمها باید remediation را در ابزارهای فعلی خودشان مدیریت کنند. DefectDojo در اینجا نقش لایه امنیتی را بازی میکند، نه لایه جایگزین مدیریت پروژه.
مثال عملی:
Semgrep یک XSS بحرانی در یک controller پیدا میکند. DefectDojo آن را ثبت و verify میکند، بعد یک issue در Jira میسازد. توسعهدهنده آن را در sprint بعدی میگیرد، رفع میکند و وضعیت را به Done میبرد. DefectDojo نیز بر اساس sync وضعیت را به Mitigated یا Closed نزدیک میکند. این چرخه باعث میشود history اصلاح آسیبپذیری از بین نرود و تیم امنیت در هر لحظه بداند وضعیت واقعی چیست.
Deduplication و Findings👇
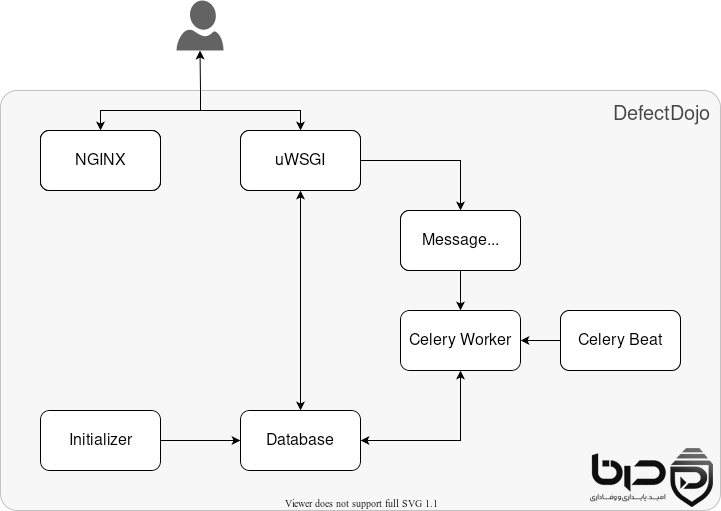
۶. استقرار DefectDojo روی سرور ابری
استقرار DefectDojo در محیط production نیازمند نگاه جدیتر از یک نصب ساده آزمایشی است. برای OpenSource edition، Docker Compose معمولاً سادهترین و عملیترین مسیر است، اما خود مستندات تأکید میکنند که فایل پیشفرض باید متناسب با محیط production شخصیسازی شود.
استقرار productionready
در production، بهتر است دیتابیس جداگانه داشته باشی، چون جدا کردن database server باعث پایداری بیشتر، مقیاسپذیری بهتر و performance مناسبتر میشود. همچنین باید به تنظیمات Nginx، headerهای امنیتی، policyهای ذخیرهسازی و backupها توجه شود.
منابع پیشنهادی :
مستندات production برای یک استقرار همراه با دیتابیس جداگانه حداقلهایی مانند 2 vCPU، 8GB RAM و 10GB فضای دیسک را پیشنهاد میکنند. البته این فقط نقطه شروع است و در محیطهایی با importهای سنگین، اسکنهای مکرر یا تعداد زیاد یافتهها، منابع بیشتری لازم خواهد بود.
رمزنگاری و امنیت
یکی از نکات مهم این است که کلید AES256 پیشفرض باید با یک مقدار منحصربهفرد جایگزین شود، چون از آن برای رمزنگاری credentialها و API keyهای متصل به ابزارهای خارجی استفاده میشود. این نکته بسیار مهم است، چون یک vulnerability management platform خودش نباید به نقطه ضعف امنیتی تبدیل شود.
پلتفرمهای پشتیبانیشده
طبق مستندات، Debian روی AMD64 بهعنوان کانفیگ officially supported و tested معرفی شده است. برخی variantهای Alpine بیشتر در سطح community قرار دارند و پوشش تست خودکار کامل ندارند. برای یک محیط سازمانی جدی، این نکته نباید نادیده گرفته شود.
مثال عملی:
اگر بخواهی DefectDojo را روی یک VM لینوکسی بالا بیاوری، بهترین الگو این است: Docker Compose productionready، دیتابیس جداگانه، volumeهای پایدار برای media و backup منظم برای پایگاه داده. سپس workerها را متناسب با حجم importها تنظیم کنی تا queueها دچار backlog نشوند. این مدل برای یک تیم DevSecOps کوچک تا متوسط کاملاً منطقی و قابلاجراست.
معماری استقرار👇
۷. سناریوی عملیاتی پیشرفته
برای فهم بهتر قدرت DefectDojo، یک سناریوی واقعیتر را تصور کن: یک تیم توسعه روی پروژه ASP.NET MVC کار میکند. هر commit جدید از طریق CI/CD به Semgrep فرستاده میشود تا codelevel issues کشف شوند. همزمان، ZAP هم روی محیط staging اجرا میشود تا مشکلات runtime و HTTPlevel بررسی شوند. خروجی هر دو ابزار به DefectDojo ارسال میشود.
در اینجا DefectDojo با autocreate context میتواند برای repository موردنظر یک Product و یک Engagement بسازد. سپس هر execution pipeline بهعنوان Test ثبت میشود و با Reimport، نتایج جدید با scan قبلی مقایسه میشوند. اگر vulnerability قبلاً وجود داشته باشد، system آن را duplicate یا unchanged در نظر میگیرد؛ اگر new issue ظاهر شود، آن را بهعنوان finding جدید ثبت میکند.
حالا اگر همان finding به Jira هم push شده باشد، تیم توسعه دقیقاً همان جایی کار میکند که باید. این یعنی از مرحله کشف تا triage، از triage تا remediation و از remediation تا verification، یک زنجیره قابلردیابی ایجاد شده است. این زنجیره، هسته واقعی DevSecOps است.
۸. گزارشگیری، SLA و مدیریت ریسک
DefectDojo فقط یک repository برای findingها نیست. این پلتفرم برای reporting، enforcement SLA، مدیریت false positive، risk acceptance، branch/repository tracking و ایجاد source of truth در امنیت نرمافزار طراحی شده است. همین موضوع باعث میشود سازمان بهجای واکنشهای پراکنده، یک view منسجم از posture امنیتی خودش داشته باشد.
SLA tracking
وقتی یک vulnerability برای مدت طولانی unresolved بماند، DefectDojo میتواند به تیمها کمک کند تا از منظر SLA، عمر آسیبپذیری و overdue status آن را ارزیابی کنند. این قابلیت برای سازمانهایی که compliance، audit یا governance دارند بسیار مهم است.
Risk acceptance
همه findingها لزوماً بلافاصله قابلرفع نیستند. گاهی یک vulnerability باید موقتاً پذیرفته شود، مثلاً بهدلیل dependency خارجی، محدودیت release یا ملاحظات business. DefectDojo به تیمها اجازه میدهد این پذیرش ریسک را ثبت و پیگیری کنند تا تصمیم امنیتی مستند و قابل audit باشد.
Report Builder و داشبوردهای مدیریتی
در نسخه Pro و حتی در بخشهای گزارشگیری نسخه OpenSource، میتوان خروجیهایی ساخت که برای CISO، مدیر فنی، QA lead و تیم compliance قابلفهم باشند. مهمترین ارزش این قسمت این است که داده خام را به indicatorهای مدیریتی تبدیل میکند: تعداد Criticalها، trend ماهانه، MTTR، overdue issues و نرخ duplicateها.
مثال عملی:
اگر در سه ماه گذشته تعداد Criticalها در `Auth Service` بالا مانده اما زمان متوسط رفع (MTTR) تغییر نکرده است، DefectDojo این روند را آشکار میکند. از روی این trend میتوان فهمید مشکل از ضعف triage است، یا کمبود نیروی توسعه، یا عدم هماهنگی بین تیمها. این همان جایی است که امنیت از سطح عملیات به سطح تصمیمسازی مدیریتی میرسد.
۹. سوالات متداول (FAQ Schema)
DefectDojo دقیقاً چه کاری انجام میدهد؟
DefectDojo گزارشهای امنیتی را از ابزارهای مختلف جمع میکند، آنها را نرمالسازی میکند، موارد تکراری را تشخیص میدهد و برای triage، remediation، reporting و issue tracking در یک داشبورد متمرکز قرار میدهد.
DefectDojo برای چه تیمهایی مناسب است؟
این ابزار برای تیمهای DevSecOps، AppSec، pentest، compliance و هر سازمانی که چند ابزار امنیتی دارد و میخواهد یک source of truth واحد بسازد، بسیار مناسب است.
Import و Reimport چه تفاوتی دارند؟
Import یک گزارش را برای نخستینبار وارد میکند، اما Reimport همان Test را با دادههای جدید بهروزرسانی میکند و برای scanهای تکرارشونده ایدهآل است.
آیا DefectDojo با Jira sync میشود؟
بله. DefectDojo میتواند findingها را به Jira ارسال کند و وضعیت آنها را بهصورت bidirectional sync مدیریت کند.
آیا DefectDojo فقط با Jira کار میکند؟
خیر. در OpenSource، Jira پشتیبانی میشود و در Pro edition گزینههای بیشتری مانند Azure DevOps، GitHub، GitLab Boards و ServiceNow نیز وجود دارد.
آیا نصب آن سخت است؟
برای OpenSource، Docker Compose مسیر سادهتری است؛ اما برای production باید تنظیمات را بر اساس نیازهای واقعی محیط سفارشیسازی کرد و بهتر است از دیتابیس جداگانه استفاده شود.
نتیجهگیری & Call To Action
- DefectDojo در عمل یک dashboard معمولی نیست؛ بلکه یک لایه orchestration برای vulnerability management است. قدرت اصلی آن در این است که دادههای امنیتی پراکنده را به یک جریان قابلاقدام تبدیل میکند: از ingest اولیه تا deduplication، از triage تا issue tracking، از import/reimport تا trend reporting. به همین دلیل، اگر یک تیم امنیتی با چندین اسکنر، چندین repository و چندین release cycle کار میکند، DefectDojo میتواند بهعنوان ستون فقرات عملیات امنیتی عمل کند.
- در محیطهایی که امنیت هنوز در فایلهای Excel، PDF و گزارشهای پراکنده گیر کرده است، DefectDojo میتواند همان نقطهای باشد که این پراکندگی را به نظم تبدیل میکند. با اتصال به CI/CD، با deduplication هوشمند، با API قابلاتوماسیون و با issue tracking واقعی، امنیت از حالت واکنشی خارج میشود و به یک فرآیند استاندارد، قابلسنجش و قابلاعتماد تبدیل میگردد.
- حالا نوبت اقدام است : از یک Product ساده شروع کن، برای pipeline خودت یک Engagement بساز، اولین گزارش Semgrep یا ZAP را Import کن و بعد Reimport را برای scanهای تکراری فعال کن. در مرحله بعد، Jira sync و deduplication tuning را اضافه کن تا DefectDojo واقعاً به ستاد فرماندهی امنیت پروژهات تبدیل شود.
اگر میخواهید یک قدم جلوتر از رقبا باشید، باید امروز اقدام کنید.😁
زیرساخت خود را بهینه کنید، pipeline های خود را امن کنید و DefectDojo را به بخشی از DNA تیم خود تبدیل کنید .